






최근 구글과 네이버, 번역솔루션 전문회사인 시스트란인터내셔널이 잇따라 '인공신경망 기계번역(NMT)' 엔진을 내놓으면서 더 정교한 번역 서비스를 제공할 수 있게 됐다고 강조하고 있다. 이들은 특히 통계기반 번역(SMT)과 비교해 훨씬 자연스럽게 번역이 이뤄진다는 점을 내세운다.
이전까지 영문기사를 구글 번역기나 네이버 번역기로 돌리면 어색한 문장들이 많이 눈에 띄었다. 심지어는 번역기로 영문을 일본어로 먼저 바꾼 뒤에 다시 한국어로 바꾸는 것이 더 자연스럽다고 말할 정도였다.
인공지능(AI)의 기반이 되는 머신러닝, 딥러닝 등 기술이 등장하기 시작하면서 사람이 번역하는 것에 비해 부자연스러운 점이 많았던 번역기의 품질이 개선되기 시작했다. 뭐가 달라진 것일까?

■사람 뇌 닮은 번역기술 'NMT'
구글, 네이버에 더해 수 십 년 간 번역서비스를 제공해 온 시스트란이 공통적으로 강조하는 것은 NMT다. 영어로는 'Neural Machine Tranlastion'이라고 불리는 NMT는 사람의 뇌가 학습하는 과정을 본딴 기술을 번역에 적용한 것이다.
기존 구글 번역, 네이버 번역 등은 통계 기반 기계번역(Statistical Machine Translation, SMT) 혹은 구문 기반 기계번역(Phrase Based Machine Translation, PBMT)이라고 부르는 방식을 썼다. 업력이 48년이나 된 시스트란은 SMT와 룰 기반 기계번역(Rule Based Machine Translation, RBMT)을 섞은 일명 하이브리드 번역기술을 사용하다가 NMT로 전환했다.
원리는 어렵지 않다. 한국어-영어 번역 과정을 예로들면 SMT나 PBMT, RBMT는 단어나 구문이 가진 여러가지 의미를 저장해 놓는다. 일종의 번역사전을 만들어 놓는 것이나 다름없다. 다음으로 사용자가 문장을 입력하면 이를 단어나 구문 단위로 쪼갠 뒤 통계적으로 가장 본래 의미에 가깝다고 판단되는 번역결과를 제시한다.
시스트란 인터내셔널 문상준 부장에 따르면 SMT는 '말뭉치(corpus)'를 미리 번역 엔진에 입력해 놓은 뒤 통계적으로 봤을 때 번역을 요청한 문장 내에 단어나 구문과 가장 비슷하다고 판단한 결과를 내놓는다는 설명이다. 말뭉치는 사람이 읽을 수 있는 텍스트를 컴퓨터도 이해할 수 있는 형태로 모아 놓은 자료를 말한다.
기존에는 통계적인 방법을 쓰는 탓에 우리나라말로 '밤'이 낮의 반대말인 밤(night)을 뜻하는지, 먹는 밤(chestnut)을 말하는 것인지를 분간해내지 못하는 경우가 적지 않았다. 더구나 한국어-영어 번역의 경우 주어와 서술어 등 어순이 다르다는 점도 반영해야하지만 SMT는 전체 문장이 흘러가는 맥락(context awareness)에 대한 이해가 부족했다는 것이 전문가들의 공통된 의견이다.
글, 네이버, 시스트란이 주목하는 NMT는 이러한 점을 보완하는 번역 기술이다. 가장 큰 차이점은 단어나 구문 단위로 쪼개는 것이 아니라 문장 단위로 번역한 결과를 보여준다는 점이다. 머신러닝 기술이 적용된 엔진을 통해 전체 문맥을 파악한 다음 문장 내에 단어, 순서, 의미, 문맥에서의 의미차이 등을 반영한다는 설명이다.
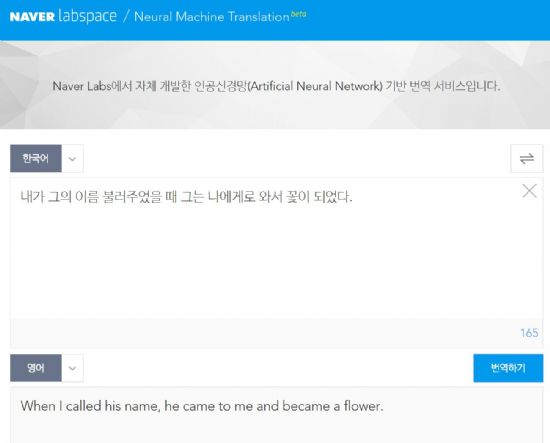
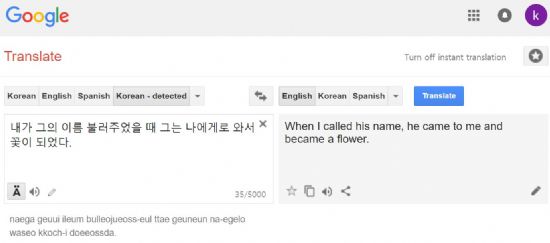

■구글-네이버-시스트란 번역기술, 얼마나 좋아졌나
구글의 경우 지난 10년 간 적용했던 PBMT 방식과 비교해 NMT를 적용해 훨씬 좋은 품질의 번역결과를 제공할 수 있게 됐다고 강조했다.
버락 투로프스키 구글 번역 프로덕트 매니지먼트 총괄은 "NMT 기술 덕분에 구글 번역은 위키피디아 및 뉴스매체의 샘플문장을 기준으로 주요 언어 조합을 평가대상으로 했을 때 번역 오류가 55%에서 85% 가량 현저히 감소하는 등 지난 10년 간 쌓아온 발전 이상의 결과를 단번에 이룰 수 있었다"고 밝혔다.
구글은 자사 NMT를 적용할 경우 위키피디아와 뉴스의 샘플문장을 번역해 본 결과 기존 PBMT 대비 번역오류를 55%~85% 가량 줄였다고 설명했다.
네이버랩스가 개발한 모바일번역앱 '파파고'에 적용된 네이버의 NMT 기술인 'N2MT'에 대해 네이버측은 "기존 SMT에 일부 딥러닝을 적용하는 방법과 달리 전체 번역 프레임워크를 딥러닝 방식으로 구축해 번역 정확도를 2배 이상 높여 더 자연스러운 번역결과를 체험할 수 있게 됐다"고 설명했다.
네이버랩스가 지난해 발표한 '문자 단위의 Neural Machine Translation'이라는 논문에 따르면 NMT가 SMT와 구분되는 특징은 최소한의 전문지식만 필요하다는 점이다. 번역을 위해 필요한 신경망의 구조만 잘 결정해 주면 알아서 머신러닝 혹은 딥러닝 과정을 거쳐 입력된 데이터가 많을수록 더 자연스러운 번역이 가능해진다는 설명이다.
네이버 관계자는 "파파고를 활용한 NMT 기반 번역이 이전 방식인 SMT와 비교해 특히 한국어-중국어 간 번역에서 정확도가 높다"고 말했다. 자체 테스트 결과 한국어를 중국어로 번역할 경우 평균 점수 대비 160% 높은 정확도를 보였고, 중국어를 한국어로 번역할 경우에는 233%가 높았다는 것이다.
1968년부터 번역서비스를 제공해 온 시스트란 인터내셔널은 미국에 세워졌다가 프랑스에 인수된 뒤 2014년부터는 국내 자동번역 소프트웨어 회사인 CSLi에게 500억원에 인수됐다.
48년 동안 자동번역분야에서 업력을 쌓아왔던 이 회사는 지난 8월 글로벌 시장에 'PNMT'라는 엔진을 출시한데 이어 최근에 한-영 번역 기능을 추가했다.
관련기사
- 네이버 파파고, 한-중 번역 더 자연스러워졌다2016.12.25
- 더 똑똑해진 구글 번역, 실제로 써보니2016.12.25
- AI로 진화된 구글 포토·번역, 얼마나 똑똑해졌나?2016.12.25
- 美, 앤트로픽 '미토스5' 빗장 풀어…"100여 곳에 허용"2026.06.27
이 회사 문상준 부장은 "구글, 네이버도 NMT로 작업을 진행하고 있는데 시스트란의 경우 유료 서비스를 이용하면 법률, 금융 등 분야별로 특화된 '사용자 사전'을 활용해 전문성을 높였다"고 설명했다. 해당 분야에 고유하게 쓰이는 용어 등을 추가해 전문성이 필요한 문장에 대해서도 보다 정확하게 번역해 줄 수 있다는 것이다. 이와 함께 "언어별로 다른 고유의 특성을 반영해 더 매끄럽게 번역을 해 줄 수 있다"고 덧붙였다.
구글은 아직까지 NMT에서 개선해야할 과제들이 있다고 설명했다. "사람 번역가라면 빼놓지 않았을 고유명사, 희귀용어를 오역하거나 문단 또는 문맥을 고려하지 않은 문장 번역 등과 같은 오류가 발생한다"는 것이다.





