



네이버의 거대언어모델(LLM) '하이퍼클로바X'가 메타의 오픈소스 모델 '라마'와 오픈AI의 폐쇄형 모델 GPT보다 번역, 추론, 수학, 일반상식 등에서 높은 성능을 기록했다는 보고서 결과가 나왔다. 6개 넘는 벤치마크 점수를 평균화한 방식을 활용해 결과 신뢰성도 높다는 평가다.
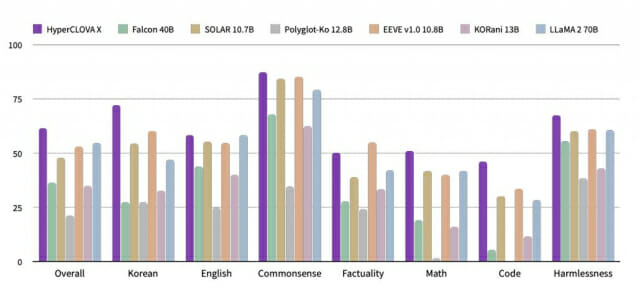
네이버는 하이퍼클로바X 성능을 오픈소스·폐쇄형 모델과 비교한 평가 결과를 4일 공개했다. 벤치마크 테스트 분야는 한국어를 비롯한 외국어, 추론, 일반상식, 수학, 코딩 등이다.
네이버는 하이퍼클로바X가 한국어뿐 아니라 영어, 중국어 등 다국어 부문에서 상위권을 기록했다는 입장이다. 연구팀은 자사 LLM이 한국어와 영어 정보를 활용해 제3의 언어로 추론하는 능력을 타사 모델과 비교했다. 이 모델은 일본어와 아랍어, 힌디어, 베트남어를 비롯한 아시아 국가 언어 능력 부문서 오픈소스 모델을 포함에 리포트에서 선정한 9개 모델 중 가장 높은 점수를 받았다. 중국어 부문에서는 동일한 폐쇄형 모델 중 2위를 기록했다.
기계 번역 평가도 마찬가지다. 한국어를 일본어로, 일본어를 한국어로 번역하는 능력은 실제 서비스 중인 번역 모델 등 리포트에서 선정한 10개의 모델 중 1위를 기록했다. 영어를 한국어로 번역하는 정확도도 동일한 10개 모델 중 가장 높은 점수를 받았다.
네이버는 자사 LLM이 오픈소스 모델뿐 아니라 오픈AI의 GPT-3.5와 GPT-4 등 폐쇄형 모델보다 특정 부문에서 성능을 능가했다는 입장이다.
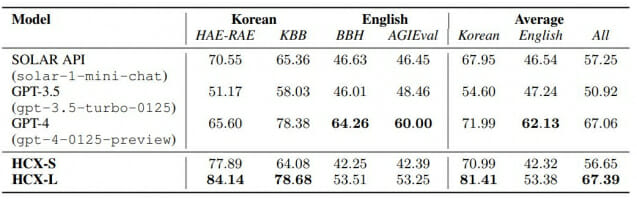
우선 한국어 능력 부문에서 14개 모델 중 가장 높은 점수를 기록했다. 영어 능력 분야에선 폐쇄형 모델 중 두번째로 높은 점수를 받았다. 1위는 오픈AI의 GPT-4다.
"평가 결과 신뢰성 높였다…벤치마크 다양화"
네이버는 성능 평가 신뢰성이 높다는 입장이다. 네이버 관계자는 "여러 벤치마크 데이터셋 기반 점수를 평균화하는 방식으로 종합 점수를 도출했다"고 설명했다.
예를 들어, 하이퍼클로바X와 오픈소스 모델의 일반상식 성능을 비교할 경우, ARC나 CSQA, Hellaswag, Winogrande, PIQA의 5개 벤치마크 점수를 평균화해서 종합 점수를 도출했다. 한국어 능력 측정을 비교하기 위해 한국판 AI 시험으로 알려진 KMMLU를 비롯한 글로벌 AI 언어 이해 능력 평가인 MMLU, 마이크로소프트의 AI 성능 평가 AGIeval 등 6개 벤치마크 점수를 종합했다.
관계자는 "최근 특정 리더보드에서 순위를 높이려는 목적으로 평가 데이터를 모델 학습에 활용해 벤치마크 테스트 점수를 올리는 사례가 있다"며 "이를 감안해 복수의 벤치마크 테스트 평균치로 객관성을 지켰다"고 설명했다.
일정 수준 이상의 경쟁력을 보유한 한국어와 영어 모델을 비교군으로 선정한 것도 신뢰성을 높이기 위한 방법이다. 네이버클라우드 유강민 리더는 "하이퍼클로바X의 다국어 추론, 기계 번역 능력을 측정한 실험은 지역 또는 문화권 특화 목적으로 개발한 AI가 해당 국가 언어 외에도 여러 언어에서 일정 수준 이상의 능력을 갖출 수 있음을 실증한 것"이라고 설명했다.
"데이터셋 정제 작업 거쳐…알고리즘 편향 더 줄일 것"
네이버 연구진은 LLM 학습 과정도 설명했다. 보고서에 따르면, 하이퍼클로바X의 사전학습 데이터는 대부분 한국어, 영어, 코드 데이터로 이뤄졌다. 이중 지나치게 짧거나 반복적인 저품질 문서는 데이터셋에서 제외됐다. 개인정보가 들어있는 데이터도 삭제됐다. 또 정렬학습을 통해 사용자 의도와 지시를 더 잘 이해할 수 있도록 모델을 고도화했다.
관련기사
- 네이버, 전문조직 중심으로 조직개편…모든 기술 분야에 AI 도입 확대2024.04.03
- 네이버, AI로 금감원 업무 생산성 높인다2024.04.03
- 네이버클라우드, 섬유 패션 기업 AI 기술 확산 돕는다2024.04.03
- 업스테이지 "누구나 쉽게 LLM 평가·테스트 무료로 하세요"2024.04.03
회사는 하이퍼클로바X가 편향된 결과를 생성하지 않도록 조치를 취했다는 입장이다. 네이버 측은 "사회적 이슈와 편향, 불법적 행동 등 민감하거나 위험한 주제를 설정해 질의 데이터를 수집했다"며 "이를 기반으로 모델 취약점을 보완했다"고 했다. 앞으로 하이퍼클로바X 윤리 원칙에 기반해 혐오, 편향, 저작권 침해, 개인정보 등과 관련한 콘텐츠 생성 빈도를 더 줄이겠다고 했다.
네이버클라우드 하이퍼스케일 AI 성낙호 기술 총괄은 "하이퍼클로바X는 한국 특화 지식뿐 아니라 프로그래밍과 수학적 추론, 다국어 능력, 안전성까지 확보했다"며 "향후 다양한 지역 국가의 특화 초대규모 AI를 만드는 데에도 적극적으로 나설 것"이라고 말했다.





