



ARM이 인공지능(AI) 애플리케이션용으로 개발한 머신러닝 프로세서(NPU)를 곧 공개한다. 스마트폰, IoT 기기, 나아가 클라우드까지 확장성을 앞세워 AI 시장 공략을 강화한다. 머신러닝 프로세서와, 2세대 객체탐지프로세서(ODP), 소프트웨어 등을 포괄하는 프로젝트 트릴리움으로 머신러닝 플랫폼을 제공한다는 계획이다.
ARM은 올해 중반기 머신러닝 프로세서(NPU)를 정식 공개한다. 이달초 타이완에서 열린 ‘컴퓨텍스2018’ 행사에서 새로운 CPU, GPU, VPU 등과 함께 머신러닝 플랫폼 ‘프로젝트 트릴리움(Project Trillium)’을 발표했다.
ARM의 프로젝트 트릴리움은 머신러닝과 AI 애플리케이션을 효율적으로 구현하기 위한 소프트웨어, 하드웨어 플랫폼이다. 코어텍스-M 프로세서와 말리 GPU, ARM 다이나믹(DynamIQ) 등의 하드웨어 기술과 ARM NN API를 중심으로 한 소프트웨어 기술로 구성된다.

■"머신러닝이 엣지로 이동하고 있다"
이안 브랫 ARM 머신러닝기술그룹 디스팅귀시드 엔지니어는 지난 19일 서울에서 열린 ‘ARM 테크데이’ 간담회에서 ARM 의 머신러닝 플랫폼을 소개했다. 이안 브랫은 ARM의 머신러닝 기술 개발을 총괄하고 있다.
이안 브랫은 “ARM은 머신러닝과 AI가 모든 프로세서의 활용범위에 파괴적 혁신을 가져올 기술이라 본다”며 “프로젝트 트릴리엄은 기존의 모든 ARM IP에 머신러닝과 AI 워크로드를 강화하기 위한 프로젝트”라고 설명했다.
그는 트릴리엄의 시작은 소프트웨어 계층이었다고 설명하고, 소프트웨어에 더해 태생부터 머신러닝에 최적화해 설계한 전용 프로세서도 내놓게 된다고 밝혔다.
그는 “당초 ARM 머신러닝 프로세서로 모바일을 공략하고자 했지만, 이 아키텍처는 IoT 서버, 엔터프라이즈 등으로 확장까지 염두에 두고 있다”며 자신감을 보였다.
머신러닝 등의 최신 AI 기술은 빠르게 IT 전분야에 채택되고 있다. 주로 대규모 클라우드 서비스 환경에서 머신러닝과 AI 기능을 처리하고 있고, 스마트폰과 IoT 엣지 기기 차원에서 머신러닝을 구동하려는 시도가 이뤄지는 상황이다. 빅데이터를 모두 클라우드로 전송해 머신러닝을 하면 AI의 실시간 의사결정 시나리오에서 한계를 드러내기 때문이다.
이안 브랫은 “머신러닝 연산이 엣지로 이동하는 이유는 물리적, 경제적, 지리적 등 세가지 법칙 때문”이라며 “머신러닝과 AI를 가능하게 하려면 반응성이 높아야 하고 지연시간이 낮아야 하는데, 물리적으로 클라우드에 데이터를 모두 전송하면 지연성이 너무 높아 극복하기 어렵다”고 말했다.
그는 “경제적으로도 모든 데이터를 클라우드로 보내면 에너지 소비와 데이터센터의 부담도 커져 실용적이지 않다”며 “보안과 프라이버시가 정말 중요한데 데이터를 원격으로 주고 받다가 중간에 데이터 유실이나 오염이 일어날 수 있다”고 덧붙였다.
■ARM 머신러닝 프로세서 '효율성과 성능 다 잡았다'
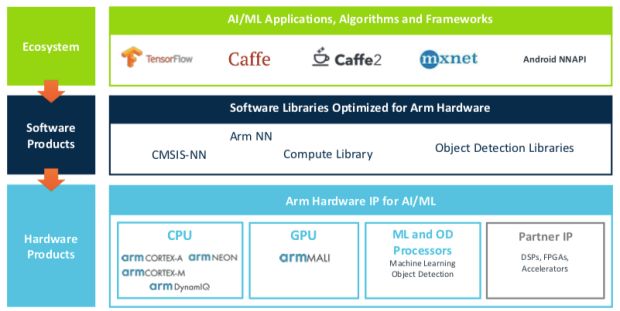
ARM 트릴리엄은 텐서플로우, 카페, MXNET, 안드로이드 NN API 등 현존하는 머신러닝 환경을 지원한다. ARM NN, CMSIS-NN, 컴퓨트 라이브러리, 오브젝트 디텍션 라이브러리 등의 소프트웨어가 코어텍스-A시리즈, 코어텍스-M 시리즈, 말리 GPU, ODP , 서드파티 IP 등의 하드웨어에서 머신러닝 프레임워크를 구동하게 한다.
그에 따르면, ARM 머신러닝 프로세서는 프로그램 가능하고, GPU 수준의 머신러닝 연산 성능을 제공하며, 손쉽게 워크로드를 배포하게 한다.
그는 “머신러닝 프로세서는 효율적인 중첩적분(convolution), 효율적인 데이터 이동, 충분한 프로그램성과 유연성 등 3가지 핵심요소를 요구한다”며 “중첩적분 효율화만으로 MAC 엔진의 성능을 40% 개선하고, 전력소비를 10~20% 줄이며, 면적을 40% 절감할 수 있다”고 말했다.
컨트롤 유닛, 외부 인터페이스를 위한 DMA 엔진, 16개 컴퓨트 엔진, 브로드캐스트 네트워크 등으로 이뤄졌다. 이중 컴퓨트 엔진은 가중치(weights)와 액티베이션 데이터 등을 저장하는 SRAM, 중첩적분 연산을 수행하는 MAC 엔진, 가중치 디코더, 기타 프로그램된 연산을 수행하는 프로그래머블 레이어 엔진 등을 갖췄다.
코어 내부의 컴퓨트 엔진 16개가 연산 작업을 나눠 수행하고, 결과값을 브로드캐스트로 동기화하는 구조다.
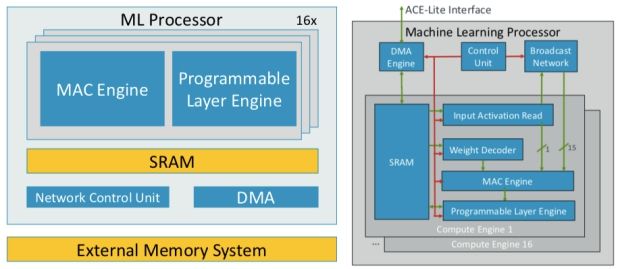
머신러닝 워크로드는 데이터 이동이 빈번하게 일어난다. 이안 브랫은 “아무리 효율적인 머신러닝 프로세서라 해도 DRAM 읽기, 쓰기 작업이 전체 전력의 50%를 소모한다”며 “ARM은 처음부터 데이터 이동이나 메모리 압축을 최적화해 모든 하드웨어의 전력 소비를 줄였다”고 설명했다.
ARM 머신러닝 프로세서는 SRAM 접근을 줄이고, 연산 매핑 기능을 수행하는 컴파일러를 개선함으로써 DRAM 대역폭을 줄여 데이터 이동을 효율화 했다.
그는 “액티베이션 압축 기술로 동적 특성을 활용하는데, 인셉션 v3 기준으로 3.3배 압축을 가능하게 한다”며 “전반적으로 7나노 공정 기준으로 3 TOPs/W의 에너지 효율성을 달성하며, 피크처리 성능은 4.6 TOP/s이다”라고 밝혔다.
그는 “머신러닝과 AI 기술은 여전히 빠르게 발전하는 기술”이라며 “코어텍스-M 기술에 기반한 프로그래머블 엔진으로 벡터 연산을 확장할 수 있으며, 인공신경망 연산을 확장할 수 있다”고 유연성도 강조했다.
■2세대 ODP, 최신 CPU와 GPU 조합으로 AI 전방위 공략
ARM은 머신러닝 프로세서와 함께 지난해 처음 공개한 ODP 2세대 제품을 내놓는다. 2세대 ODP는 풀HD 60 fps 영상에서 실시간으로 객체를 탐지한다. 그는 “새 ODP는 무한대에 가까운 객체를 인식할 수 있으며, 객체의 방향이나 제스처까지 탐지한다”고 말했다.
트릴리엄 플랫폼의 소프트웨어는 ARM NN 추론 엔진을 핵심으로 한다. 외부 AI API와 하드웨어 사이에 존재하며 말리 GPU와 머신러닝 프로세서의 연산을 관할한다. ARM은 구글과 협력을 통해 안드로이드 NN API를 코어텍스-A CPU에서 빠르게 처리할 수 있도록 개선하고 있다. 임베디드 리눅스 등 비 안드로이드 시스템에서 사용가능하도록 ARM NN SDK도 제공한다.
머신러닝 프로세서와 함께 ARM은 코어텍스-A76 CPU와 말리-G76 GPU 등을 선보였다. ARM의 최신 CPU와 GPU는 머신러닝 처리 성능을 대폭 개선했다.
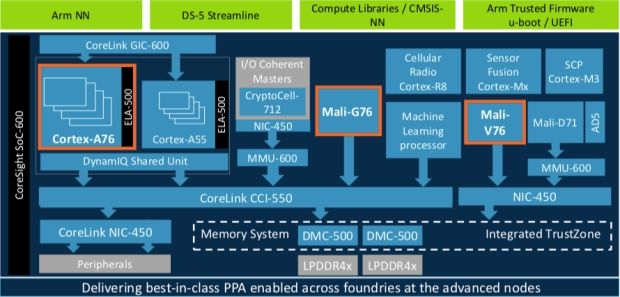
코어텍스-A76은 머신러닝 성능을 4배 개선했다. 기본적으로 전세대 대비 성능을 35%, 에너지 효율성을 40% 개선했다. 말리-G76은 머신러닝 성능을 2.7배 높였다. 성능은 30%, 에너지 효율성은 30% 개선됐다.
관련기사
- 인공지능, 사람과 토론하는 단계까지 발전했다2018.06.20
- 구글 딥마인드, 2D→3D모델링 자동 생성 AI 개발2018.06.20
- 기업 IT, AI시대 한복판에 서다2018.06.20
- AI 품은 모바일 AP 각축전 시작됐다2018.06.20
ARM은 코어텍스, 말리, 머신러닝 프로세서, ODP 등을 원하는 목적에 맞게 조합해 원하는 머신러닝 시나리오에 최적화할 수 있다고 강조했다. 이미 유기적 칩셋 조합으로 성능을 확대할 수 있게 한 만큼 광범위한 AI 시스템에 활용될 수 있을 것으로 본다.
ARM IPG 클라이언라인오브비즈니스 마케팅프로그램 수석디렉터는 “코어텍스 A76에서 마이크로아키텍처를 변경하는 등 전체 ARM IP에서 머신러닝 성능을 대폭 개선하는 노력이 이뤄졌다”며 “5G 시대의 도래와 산업의 변화 속에, 더욱 연결된 세상을 인류가 경험하는 진화의 한가운데 ARM 이 중요한 역할을 하기를 기대한다”고 강조했다.





