



마이크로소프트가 문장에서 이미지를 자동 생성할 수 있는 인공지능(AI) 기술을 개발해 관심을 모은다.
이 기술을 사용하면 “노란 몸에 검은 날개를 지닌 짧은 부리 새”라고 입력했을 때 마치 실재하는 조류인 것 같은 자연스러운 이미지를 자동 생성할 수 있다.
사진이나 이미지에서 설명(캡션)을 자동 생성하는 AI는 구글 등에 의해 이미 개발됐다. 마이크로소프트 역시 비슷한 기술을 개발, 오피스에 도입하는 기술도 갖고 있다.
마이크로소프트 AI 블로그에 따르면 마이크소프트 연구소가 최근 개발한 ‘드로잉 봇’(Drwing bot)은 원하는 이미지의 설명을 텍스트로 입력하면 이에 맞는 이미지를 AI가 자동으로 생성해준다.

앞서 언급한 대로 ‘노란 몸에 검은 날개를 가진 짧은 부리 새’라는 텍스트를 입력하고 드로잉 봇에 이미지 생성을 요구하면 컴퓨터가 상상한 새가 픽셀 단위로 생성돼 완성된다.
이에 마이크로소프트 연구소 딥러닝 기술센터의 주임 연구원 샤오동 히(Xiaodong He) 씨는 “앞으로 빙에서 검색했을 때 나타난 이미지는 실제 조류가 아닐지도 모른다”고 말했다.
기존의 ‘이미지→자막’ 변환 AI 기술은 많은 특징 중에서 확실한 정보를 엄선하는 방식이었다. 그러나 ‘자막→이미지’ AI 기술인 드로잉 봇은 일부 정보를 바탕으로 부족한 정보를 스스로 보충해 재구성하는 과정을 거치기 때문에 기술 난이도가 높다.
드로잉 봇을 실현하기 위한 기술의 핵심은 'Generative Adversarial Network'(GAN)라는 기술이다. GAN은 상반되는 목적을 가진 두 모듈(판별망, 생성망)이 대결하는 구조를 통해 이미지 생성을 학습하는 이미지 생성 기술의 한 종류다.
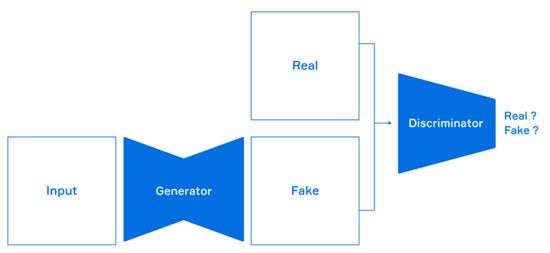
GAN에서 생성된 이미지는 ‘판별망’(Discriminator)이라는 품질을 판단하는 모델을 통해 보다 정교하게 바뀐다. 판별망은 주어진 이미지가 실제인지, 거짓인지 판별하는 법을 학습한다. 이를 통해 실제와 거짓 이미지를 잘 구분해 내는 것이 궁극적인 목표다.[☞GAN 참고 기사 보기: 네이버 천재 인턴, AI 개발자들도 ‘깜짝’]
자막→이미지 과정에 있어 ‘파랑새’와 ‘상록수’ 같은 간단한 텍스트에서 이미지를 생성하는 작업은 비교적 쉬운 작업이다. 그러나 ‘노란 날개’, ‘붉은 배’ 등의 복잡한 조건이 가해지면 전체 문장을 하나의 정보로 모으는 과정에서 일부 정보가 손실되는 문제가 발생한다.
그래서 드로잉 봇은 인간이 그림을 그릴 때 반복적으로 설명을 참고하고, 이미지를 표현하는 단어에 세심한 주의를 기울이는 행동을 참고, ‘주의’의 개념을 수학적으로 표현하는 ‘AttnGAN’이라는 매개 변수를 만들었다. 이렇게 하면 입력된 텍스트를 개별 단어로 분할해 이미지의 자세한 내용을 구축할 수 있다. 또 AttnGAN은 인간이 가진 ‘상식’의 개념을 기계학습(머신러닝)으로 AI가 습득한다.
이와 같이 드로잉 봇에서는 ‘주의’와 ‘상식’ 두 기계학습 과정을 결합한 AttnGAN이 사용된다. 설명에 있던 이미지를 생성하고, 이미지의 품질을 판단하는 모델 판별망을 거치면 마치 실제 사진과 착각이 들 정도의 고품질 이미지 생성이 가능하다.
또 마이크로소프트에 따르면 AttnGAN에서 생성된 이미지 품질은 기존의 GAN 기술을 통해 만들어진 이미지 품질에 비해 3배나 뛰어나다.
관련기사
- 네이버 천재 인턴, AI 개발자들도 ‘깜짝’2018.01.21
- AI로 가짜 유명인사 사진 만들기, 더 정교해졌다2018.01.21
- 인공지능이 생방송 출연자 '페이스오프'2018.01.21
- 아마존, 패션 판도 AI로 뒤집는다2018.01.21
드로잉 봇은 놀라운 수준이지만, 몇 가지 작은 결함을 가진 미완성 기술이다.
이에 연구소는 앞으로 고도화 과정을 거쳐 스케치의 보조 역할을 하고, 음성 인식으로 만든 사진을 보다 정교하게 만드는 데 활용한다는 계획이다. 나아가 인간이 일체 손을 사용하지 않고 텍스트 기반의 각본으로 애니메이션 영화를 제작하는 등의 용도로 쓰는 것도 하나의 목표다.[☞관련 자료 보기: Microsoft researchers build a bot that draws what you tell it to]





