이세돌 9단과 대국을 앞둔 구글 딥마인드 프로그램인 알파고는 사람의 신경망을 모방한 인공지능 기술인 딥러닝으로 중무장하고 있다.
1997년 IBM 슈퍼컴퓨터 딥블루가 체스왕을 누른 것이나 IBM 왓슨이 제퍼디 퀴즈쇼에서 우승한 것보다 한차원 높은 기술에 기반한다는 평가다.
구글 딥마인드에 따르면 딥블루가 체스왕을 이길 때는 모든 경우의 수가 투입됐다. 체스 거장들이 필요 정보들을 미리 입력하고 나서 대국에 임했다.
왓슨이 2011년 제퍼디에서 우승할 때는 특별한 사례들을 DB화해 질문이 나왔을 때 특정 주제에 맞는 답을 검색해 찾아주는 방식이 적용됐다. 그러나 이런 방법으로는 바둑이라는 고차원 게임을 뛰어넘을 수 없다는 것이 딥마인드 설명이다.
알파고의 핵심인 딥러닝은, 머신러닝의 방법 중 하나로 아주 복잡한 모델링까지 가능하게 한다. 뇌가 작동하는 방식을 모델링에 활용했다고 보면 된다. 이렇게 되면 컴퓨터가 상황에 따라 판단을 할 수 있게 된다.
말은 쉬워보이지만 딥러닝으로 구체적인 성과를 내기 위해서는 엄청난 양의 데이터와 고도의 소프트웨어 역량 그리고 강력한 컴퓨팅 파워가 모두 요구된다. 데이디터와 엔지니어링 역량을 모두 갖춘 구글이나 페이스북 같은 회사들이 딥러닝 레이스를 주도하는 이유다.
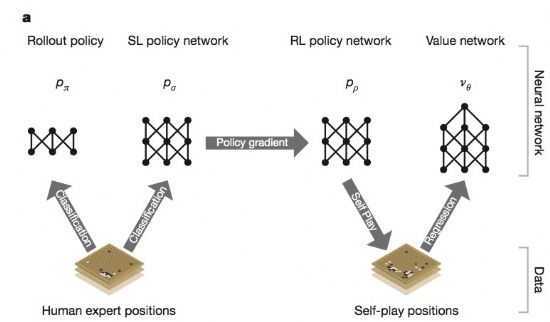
구글 딥마이드는 알파고에 두 개 신경망(가치망+정책망)과 몬테카를로 트리 검색(MCTS) 기술을 투입했다.
MCTS는 다양한 경우를 감안해 가장 적합한 결정을 할 수 있도록 해 주는 알고리즘이다. 알파고는 MCTS를 함께 활용해 어디에 바둑알을 놓을 지 골라낸다. 이때 각 위치 정보에는 행동가치, 방문 횟수, 그리고 사전 확률 등이 담겨 있다 정책망은 부르는 다음번 돌을 놓을 위치를 선택하고 가치망은 승자를 예측한다.
알파고는 내부 신경망들과도 서로 수천만회에 달하는 대국을 벌였다.알파고는 실전 테스트에서 나온 결과물을 갖고 강화학습이라는 시행착오 프로세스를 통해 새로운 전략을 학습한다. 구글 딥마인드는 "이를 위해서는 강력한 컴퓨팅 능력이 필요해기 때문에 구글 클라우드 플랫폼을 폭넓게 활용했다고 설명했다.
앞서 언급했듯 딥러닝 기술을 활용했다고 하루아침에 전문가 수준의 인공지능이 탄생하는건 아니다. 수많은 시행착오와 학습을 거쳐야 한다.
알파고도 마찬가지다.
지난해 10월 판 후이 2단과 대결했을 때 알파고는 프로 수준이라고 보기 어려운 장면도 연출했다. 그러나 학습을 할 수 있는 시간이 충분했던 만큼, 지금은 기량이 그때보단 크게 늘었을 것이란게 전문가들의 평가다.
알파고의 실력이 어느정도 향상됐는지에 대해 구글은 말을 아끼고 있다. 알파고의 지금 실력을 파악하기 어렵다는 건 이세돌 9단에게 불리한 요소로 꼽힌다.
관련기사
- '이세돌-알파고 대국' 어디서 볼 수 있나2016.03.09
- 알파고 vs 이세돌…구글은 이미 승리했다2016.03.09
- 이세돌 vs 알파고, 주사위는 던져졌다2016.03.09
- 이세돌 vs 알파고 "바둑일 뿐…오해하지 말자"2016.03.09
알파고는 이번 대국을 위해 이세돌 9단의 바둑 습관을 따로 분석하지는 않았다. 특정 사례가 아니라 수많은 연습 게임과 강화학습을 통해 진화해 나가고 있다. 이번 대국을 통해 확보한 데이터도 향후 알파고 기량을 향상시키는데 중요하게 활용될 전망이다.
알파고와 이세돌 9단과의 대국은 5차례 진행된다. 구글 딥마인드가 첫번째 대국에서 확보한 데이터로 알파고 실력을 하루아침에 업그레이드하기는 쉽지 않다. 딥러닝의 특성상, 트레이닝 시간이 필요하기 때문이다. 그러나 몇개월 후에는 상황이 달라질 수 있다. 이세돌 9단과 대결해서 확보한 데이터의 가치는 대단히 클 것으로 보인다.