



네이버의 음성인식 인공지능(AI) 플랫폼 클로바가 음성변조나 성대모사를 한 목소리까지 구분할 수 있도록 하는 기술이 연구되고 있다.
이봉진 네이버 스피치팀 개발자는 12일 서울 삼성동 코엑스에서 열린 개발자 행사 ‘데뷰 2018’에서 클로바 화자인식이란 주제로 발표했다.
이 개발자는 “일부 악의적인 사용자들이 녹음, 성대모사, 음성변조, 개인화 음성합성 등으로 혼란을 줄 수 있다”며 “하지만 다행히 이런 부분에도 연구가 되고 있다”고 밝혔다.

발표에서 이 개발자는 현재 클로바 음성인식이 가진 한계와 개선 방향에 대해 소개했다.
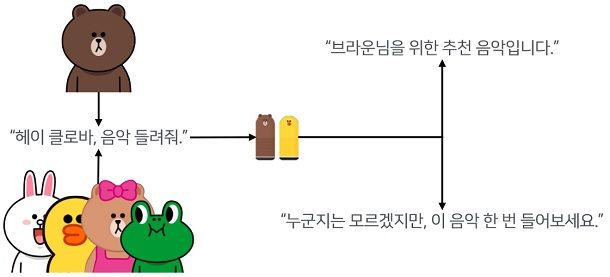
화자인식에 대한 스피치팀의 목표는 사람의 목소리를 인식한 뒤 개인별로 음성을 구분하는 것이다. 쉽게 말해 누가 클로바에 명령하느냐에 따라 다른 대답을 내놓을 수 있어야 한다는 것. 서로 다른 화자가 “헤이 클로바, 음악 들려줘”라고 명령한 경우 이미 알고 있는 화자에게는 “○○님을 위한 음악 추천입니다”라고 답하고, 처음 인식한 화자에게는 “누군지는 모르겠지만 이 음악을 한번 들어보세요”라고 답할 수 있도록 하고자 한다.
화자가 많아지거나 발화 거리가 멀어질수록 화자 인식 능력은 떨어진다. 스피치팀은 화자가 가까운 거리뿐 아니라 먼 거리에 있을 때도 목소리를 잘 인식하도록 관련 기술을 연구 중이다. 조용한 공간이나 클로바에서 음악이 나올 때, 클로바 외 소음이 있을 때 등 환경 변화에도 목소리 구별하는 문제에 대해서도 고민한다.
스피치팀은 화자인식 성능을 개선하기 위해 알고리즘 및 딥러닝 훈련 방법, 딥러닝 개발 도구, 서버 등에 변화를 주는 방식으로 실험한다고 이 개발자는 설명했다.
알고리즘 구조 및 세부구조에 변화를 준 실험에 대해 이 개발자는 “목소리를 인식시키는 딥러닝 구조에는 여러 가지 구조가 있는데 DNN 계열의 VGG복스, 레즈넷(ResNet) 등은 최근 개발된 구조 DNN 이전 알고리즘들에 비해 성능이 좋다”며 “사람이 발성하면 음성 특징을 추출해 DNN이 인식하고 출력해 화자 벡터를 만드는 식으로 돌아간다”고 말했다.
이어 “VGG복스 및 레즈넷의 세부 구조를 바꿔가며 실험했더니 VGG복스 대비 레즈넷을 이용했을 때 성능이 10%정도 개선됐다”며 “특히 레즈넷의 세부 구조에 변화를 주는 실험을 했을 때 기존 레즈넷에서보다도 성능이 더 좋아졌다”고 덧붙였다.
파이토치란 딥러닝 개발 툴을 기준으로 서버에서 CPU보다 GPU를 이용했을 때 133배 정도 화자인식 속도가 빠른 것으로 나타났다. 그러나 GPU 비용이 비싸서 CPU를 활용해 성능을 개선하는 것이 관건이었다. 이에 스피치팀은 파이토치 대신 카페(caffe2) 툴과 CPU를 사용하면 파이토치에서 CPU를 사용할 때보다 연산 속도가 빠른 점을 발견했다고 이 개발자는 설명했다.
관련기사
- LGU+, AI 플랫폼 '클로바'에 시각장애인 콘텐츠 제공2018.10.12
- 네이버, 클로바 AI 스피커에 키즈 콘텐츠 추가2018.10.12
- 네이버, AI 클로바와 샤오미 스마트홈 기기 연동2018.10.12
- 네이버, 클로바 앱에 ‘스마트홈’ 탭 신설2018.10.12
이 개발자는 향후 스피치팀이 해결해야 할 문제에 대해서도 짚었다. 이 개발자는 "이같은 실험들을 할 때는 '헤이 클로바'란 호출어만 가지고 실험했는데, 문장 길이가 각기 다른 명령어까지 붙여 실험하면 성능이 더 낮게 나올 것"이라며 "따라서 명령어의 시작과 끝을 명확히 인식할 수 있는 방안도 연구해야 한다"고 말했다.
아울러 클로바 성능을 개선함에 따라 사용자가 따로 버전을 업데이트해야 하느냐에 대한 기자의 질문에 이 개발자는 "네이버가 화자인식 등 성능을 개선할 때 서버 단에서 업데이트를 진행한다"며 "때문에 이용자는 기기를 바꾸거나 버전을 업데이트를 해야할 필요 없다"고 덧붙였다.





