






최근 다양한 곳에서 쓰이고 있는 기계학습을 이용해 게임 속 부정한 행위인 어뷰징을 찾는 방법이 넥슨 개발자 컨퍼런스에서 소개됐다.
웹젠앤플레이의 김정주 기술위원회 TD는 28일 성남시 판교 넥슨 사옥에서 열린 넥슨 개발자 컨퍼런스 2016(NDC16)에서 ‘기계학습을 이용한 어뷰징 검출’이라는 주제 발표를 했다.
김정주 TD는 버그나 해킹 툴을 이용한 비정상 플레이, 전체 채팅창을 광고로 도배하는 등의 어뷰징이 늘어나 사람의 개입만으로는 한계에 달하면서 사람의 개입이 최소화된 탐지 시스템을 만들기 위해 개발했다고 밝혔다.

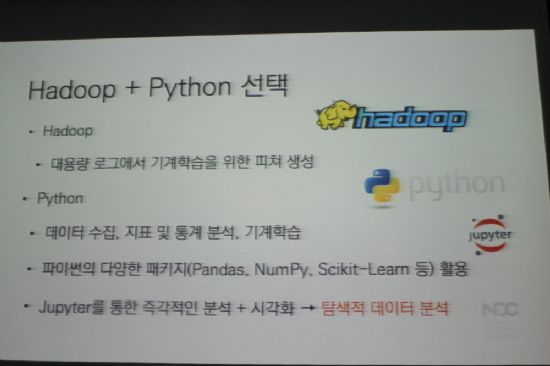
탐지 시스템은 하둡과 파이썬을 이용해 개발했다 하둡은 대용량 로그에서 기계학습을 위한 피쳐 생성을 위해 쓰였으며 파이썬은 데이터 수집, 지표 및 통계분석, 기계 학습 등에 사용했다.
김 TD는 “하둡을 사용한 이유는 데이터가 방대할 것을 대비하기 위한 것으로 만약 데이터가 크지 않다면 배치 잡을 장시간 돌리거나 매일 ETL 과정을 통해 DB에 넣어야 한다”고 설명했다. 또한 직접 하둡 클러스터를 구축할 수도 있지만 세팅과 운용이 어렵기 때문에 AWS의 EMR 등 클라우드 서비스를 이용할 것을 추천했다.
특히 파이썬은 판다스(pandas), 스티킷런(stickit0learn) 등의 패키지를 주로 활용했다. 또한 주피터를 통한 즉각적인 분석과 시각화를 통해 탐색적인 데이터 분석을 실시했다.
탐색적 데이터 분석은 데이터에 숨어있는 정보를 다양한 방면에서 검토하고 시각화를 하는 과정으로 이를 김정주 TD는 WzDAT라는 자체 시스템을 제작해 사용했다.
이렇게 만들어진 시스템은 광고글 제재에 사용됐다. 당시 신규 오픈한 게임의 채팅창에 광고가 가득 올라와 일반 이용자는 채팅으로 의사소통이 어려운 상황에 처할 정도로 빠른 제제가 필요했고 기계학습을 도입하기엔 시간이 부족했다.
또한 어뷰저는 일반적인 제제 프로그램으로 광고가 막히는 것을 방지하기 위해 메시지 중간중간에 특수기호를 난독화 시켰다.
김정주 TD는 “NPS 챗 코퍼스(NPS chat corpus)라는 자연어 툴킷을 이용해 메시지 길이 분포를 확인했다. 또한 광고 메시지는 길이가 다양하지 않고 빈도가 높기 때문에 이를 도입해 비슷한 길이의 채팅 메시지를 자주 보내면 광고일 확률이 높다고 추측했다”며 “이를 기반으로 스팸 검출 공식을 만든 후 스팸을 걸러내기 시작했으며 스팸을 걸러내는 기준 값은 캐릭터의 매시지 값은 상황에 따라 조절해 오탐의 가능성을 줄이고 있다”고 설명했다.
기계학습은 종류를 예측하는 분류와 연속된 값을 예측하는 회귀로 나뉜다. 어뷰징 검출은 분류에 속한다. 또한 기계학습 방법은 샘플 데이터를 활용한 지도 학습과 샘플 데이터가 없을 때 활용하는 자율학습으로 이뤄져 있다.
온라인 게임에서는 각종 해킹 툴을 사용해 자동 사냥을 하는 등 어뷰징이 발생한다. 다만 워낙 다양한 해킹 툴과 오토프로그램이 있어 이를 한 둘로 특정할 수 없기 때문에 기계학습을 통해 다양한 변수를 확인하고 찾아내야 한다.
웹젠은 운영팀이 기존 어뷰져 캐릭터 리스트를 가지고 있었기 때문에 이를 기반으로 디시전 트리 방식으로 지도학습을 시작했다.
만약 학습할 수 있는 데이터가 없다면 플레이 특성별 클러스터를 만들어 사용하는 클러스터링 등 자율학습을 활용하면 된다.

먼저 기계 학습을 위해서는 어뷰저의 로그의 수집 상태와 구조 및 의미를 파악하고 학습의 대상이 되는 어뷰저의 특징인 피쳐를 추출해야 한다. 로그를 분석하고 이를 가공해야 이를 기반으로 어뷰저를 찾을 수 있기 때문이다.
피쳐는 캐릭터를 기준으로 구하며 다양한 각도에서의 분석이 필요하기 때문에 하나의 정교한 피쳐보다는 다양한 피쳐를 만드는 것이 유리하다. 피쳐의 형태는 실수형으로 통일하는 것이 좋으며 카테고리 타입은 실수형으로 설정한다.
피져가 정해지면 파이썬의 스티킷런의 패키지의 디시전트리를 사용해 기존에 보유한 피쳐와 어뷰저 여부를 넣고 기계학습을 진행한다. 디시전트리를 사용하는 이유는 다양한 값이 있을 때 범위를 통일시켜주는 피쳐 정규화 과정이 없어 편리하기 때문이다.
이를 통해 확인한 초기 결과는 80%의 어뷰져를 검출하는 것으로 나타났다. 낮은 편은 아니지만 제제의 근거로 쓰이기 때문에 신뢰도를 더욱 높일 필요가 있었다.
김 TD는 정확도를 높이려 교차 검증을 위해 데이터 셋을 분리하고 그리드 서치를 통해 최적의 하이퍼 파라미터를 찾으며 91%까지 향상시켰다. 이후 디시전트리가 하부로 내려갈수록 과적합이 되기 쉬워서 뎁스를 너무 깊지 않도록 만들면서 96%까지 정확도를 끌어올렸다.
점수는 높은 편이지만 실제로 적용한 결과 오탐이 제법 나오는 것으로 밝혀졌다. 원인은 디시전트리의 과적합 문제였다. 이를 해결하기 위해 디시전트리를 조합한 랜덤포레스트로 기계학습을 바꿨다. 이는 다수의 디시전 트리로 분산학습을 시키고 이들의 평가 중 가장 많은 선택에 따라 어뷰져를 결정하는 방식이다.

이 방식의 정확도는 95%로 디시전트리보다 1% 낮은 것으로 나타났다. 하지만 예측 확률을 70% 이상의 경우로만 포함한 결과 정밀도가 100%를 달성했다. 이후 웹젠은 이 데이터를 바탕으로 2개월에 걸져 제재를 통해 해킹 툴을 사용한 파밍을 대부분 해결할 수 있었다.
관련기사
- [NDC16] 소프트웨어엔지니어는 끊임없는 배움 필요2016.04.28
- 폐막 앞둔 NDC16, 지식 공유의 장으로 거듭나2016.04.28
- [NDC16] 이용자 동향 파악 위한 실시간 트렌드 찾기2016.04.28
- [NDC16]오웬 마호니 넥슨 “게임은 IT 산업 발전에 영향”2016.04.28
김정주 TD는 “검출된 결과를 이용해 학습모델을 개선할 예정이며 이후 등장할 수 있는 변종 봇에 대한 모니터링이 필요할 것”이며 “현재 딥러닝을 활용한 시스템과 실시간 로그 모니터링을 준비하고 있다”고 말했다.
이어서 그는 “새로운 기술이라고 해서 무조건 사용하기보다는 기계 학습이 내가 하려는 일에 적합한지 판단이 중요하다”며 “그리고 데이터를 보다 보면 실제로는 연관이 없지만 유사하게 보이는 경우도 자주 볼 수 있다. 너무 데이터에만 집착하지 말고 사업과 도메인에도 이해하는 노력을 기울이면 더욱 좋은 성과를 낼 수 있을 것으로 생각한다”며 발표를 마쳤다.





