






‘터미네이터2’에 나오는 기계인간 T-800(아놀드 슈왈츠제네거)이 눈으로 사람과 주변 사물을 인식하듯, 기계가 사람의 눈을 대신할 날이 머잖아 보인다.
공상과학 영화에서나 가능할 것만 같은 이런 이미지 인식 기술이 빠른 속도로 고도화되고 있기 때문이다.
이미지넷이 주최하는 ‘라지 스케일 비주얼 레코그니션 컴피티션’(Large Scale Visual Recognition Competition, 이하 ILSVRC) 대회에서 나온 ‘수퍼비전’과 같은 이미지 인식 알고리즘이 대표적이다.
21일 주요 외신은 이미지 인식 경쟁 대회인 ILSVRC에서 발표된 수퍼비전 기술을 소개했다. ILSVRC는 이미지 인식 알고리즘의 개발을 목표로 하는 대회다. 제시된 그림이 참가자가 만든 이미지 인식 알고리즘에 포함돼 있는지 여부를 판단하는데, 인식한 개체 주위를 테두리로 둘러싸는 방식으로 알고리즘의 정교함을 겨룬다.

즉 대회에서 제시하는 그림을 누가 얼마나 잘 인식하는가를 겨루는 대회다. 이미지를 인식 시키는 물건은 주판에서 호박까지 1천 종류 이상이 준비돼 있으며, 이들은 100만 개 이상의 이미지 데이터 중에서 이를 인식하고 정답률을 겨룬다.
물체의 실상을 판단하는 행위는 인간에게 있어 쉬운 일이지만 컴퓨터에게는 매우 어려운 일이었다. 그러나 2012년 열린 ILSVRC에서 캐나다 토론토 대학의 연구팀이 선보인 ‘수퍼비전’이라는 이미지 인식 알고리즘은 이미지 인식 기술에 있어 큰 돌파구를 마련했다.
이로써 현재 머신비전(사람의 눈의 인식기능을 카메라와 컴퓨터를 통해 구현하는 기술)의 정밀도는 비약적으로 성장했다.
수퍼비전은 ‘심층 회선 신경망’이라는 기술이 사용됐다. 심층 회선 신경망을 채용한 알고리즘이 대회에서 우승한 것은 수퍼비전이 세계 최초며, 그 성적은 당시 기술 수준에서 으뜸이었다.
2010년 ILSVRC에서 우승한 이미지 인식 알고리즘의 정답률이 71.8%, 2011년 우승한 알고리즘 정답률이 74.2%였던 것에 비해 수퍼비전은 무려 정답률이 83.6%를 기록했다. 같은 해 2위였던 73.8%를 10% 포인트 가량 앞서며 격차를 크게 벌렸다.
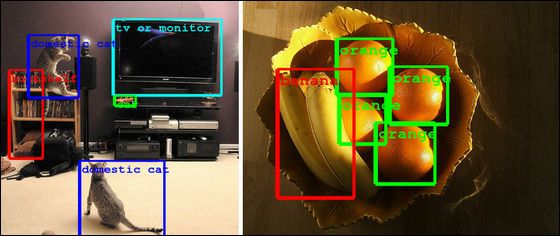
심층 회선 신경망은 각각 세분화 된 이미지의 집합으로 이뤄진 층을 여러 개 만드는 것으로 구성된다. 다양한 이미지를 인식할 수 있도록 하기 위해 각층의 모든 이미지는 부분적으로 일치하고, 시스템이 적절하게 이미지를 인식할 수 있게 될 때까지 반복해 그것들을 처리하고 학습시킨다.
원래 처음 심층 회선 신경망이 고안된 것은 1980년대였지만, 이 수준이 고도화 돼 이미지 인식까지 가능하게 된 것은 지난 몇 년 간이다.
수퍼비전은 65만 개의 뉴런으로 이뤄져 있으며, 이 신경은 5개의 층을 형성하고 있다. 또 약 6천만 개의 매개 변수를 갖고 있는데, 단계를 거쳐 매개 변수는 조정되고, 이를 통해 물체의 세부사항을 인식하게 된다. 물체를 인식하는 매개 변수가 월등히 많기 때문에 수퍼비전은 과거보다 상세한 이미지 인식이 가능하다.
수퍼비전이 등장한 2012년 이후 여러 연구 그룹에 의해 화상 인식 정확도는 향상되고 있다. 올해 구글넷(GoogLeNet)이라는 구글의 엔지니어에 의해 만들어진 이미지 인식 알고리즘이 93.3%라는 위협적인 정답률에 도달했기 때문이다.
스탠포드 대학의 올가 러사코브스키(Olga Russakovsky) 씨에 따르면 이미지 인식 알고리즘에서 중요한 것 중 하나는 ‘고품질의 데이터 세트’다. 데이터 집합의 모든 이미지가 각 이미지의 대표적인 존재로 이미지 인식될 때, 학습에 의한 이미지 데이터도 그들을 지원할 수 있어야 한다는 것.

고품질의 데이터 세트를 생성하기 위해 러사코브스키 씨는 아마존 메케니컬 터크(Amazon Mechanical Turk)를 사용해 실제 인간에게 이미지 카테고리 분류를 의뢰하는 방법을 시도했고, 그 결과 정확한 인식이 가능한 이미지 데이터 베이스 만들기에 성공했다고 설명했다.
인간의 눈과 머신비전을 비교한 러사코브스키 씨는 “우리의 연구 결과에 따르면 교육된 인간은 현재 최고의 이미지 인식 정확도를 가진 구글넷보다 정답률이 뛰어나다”면서도 “그러나 더 이상 화상 인식 작업에서 인간이 압도적으로 뛰어난 성능을 보인다고 볼 수는 없다”고 말했다.
예를 들어 개를 견종별로 분류하는 등의 정밀도는 인간보다 기계 쪽이 뛰어나다는 설명이다. 또 현재 구글넷 이미지 인식 알고리즘은 ‘작은’ 또는 ‘얇은’ 것과 같은 정교한 차이를 인식하기 위한 연구와, 현대에 흔히 있는 필터 등으로 가공된 사진을 인식하는 기술 개발로까지 발전하고 있다.
외신은 “영화 터미네이터에 등장하는 T-800은 2029년에서 보내져 온 미래의 기계지만, 앞으로 15년 간 T-800에 필적하는 머신비전의 실현이 가능할지 기대가 높아질 것으로 보인다”고 밝혔다.
관련기사
- 아이언맨 부럽지 않은 ‘AR 안경’ 예판2014.09.21
- 넷스케이프의 아버지 "구글안경, 마술같아"2014.09.21
- 구글 안경, “옷으로 사람 식별한다”2014.09.21
- [세앱] 올해 최고의 발명품 10가지2014.09.21





