





이미 네트워크는 특정인만의 전유물이 아니기에 네트워크상에서 발생하는 수많은 장애는 고스란히 컴퓨터를 사용하는 모든 사람들에게 영향을 주게 마련이다. 네트워크로 인해 발생하는 장애는 업무처리를 방해하기도 하지만 이렇다 할 해결책을 찾기란 쉽지 않은 일이다. 특집 4부에서는 네트워크를 이루는 장비들 사이에서 발생하는 장애요인과 그 해결방법들에 대해 알아본다.
네트워크를 배제한 상태에서 단 한대의 컴퓨터만 사용한다 하더라도 여러 문제들 탓에 컴퓨터가 말썽을 부리게 마련. 하물며 오늘날처럼 지구상의 거의 모든 컴퓨터들이 복잡한 네트워크를 통해 연결되어 있고 서로 영향을 주는 상황에서 생길 수 있는 문제가 얼마나 많을지는 말하지 않아도 알 수 있을 것이다.
물론, 그 수 많은 문제들 중 보다 빈도가 높고 찾기 쉬운 문제들도 있다. 그것이 바로 이번 부에서 알아볼 물리적 장비들이 일으키는 문제들이다.
네트워크에서 문제를 일으키는 가장 대표적인 원인은 주로 케이블 불량이나 규격 이상, 전원문제처럼 물리적인 요소와 이상 패킷, 불량 프레임, 상이한 프로토콜이나 호환 문제 등이다.
이런 논리적 요소를 네트워크를 구성하는 일곱 개 레이어 중 가장 아랫단에 있는 레이어 1과 레이어 2라고 부른다. 여기에서는 레이어 1과 2를 구성하는 요소와 그것들이 일으키는 문제들에 대해 알아본다.

네트워크를 하기 위해서 가장 중요하고 또 많이 쓰이는 것이 바로 케이블이다. 한편 많이 사용되는 만큼 가장 쉽게 문제의 원인이 되기도 한다. 케이블은 단순히 PC와 PC를 연결하기만 하는 것이 아니다. 장비와 장비를 연결해 주는 중요한 역할도 수행한다. 인터넷 망도 어떻게 보면 장비와 케이블의 조화라고 할 수 있다.
만약 갑자기 네트워크 장애가 발생한다면 자신의 랜 카드 LED가 정상적으로 반짝이는지 확인하거나 윈도우의 네트워크 상태 창을 통해 랜 카드의 작동 상태를 확인해야 한다. 그 다음으로 확인해 보아야 할 것이 바로 대부분의 경우 의심하지 않는 케이블이다.
필자가 모 대학교의 전산망을 유지 보수하던 때의 일이다. 건물 한 동 전체가 인터넷이 안 된다고 신고가 들어와 현장에 나가 보았다. 도착해서 제일 먼저 장비를 확인해 보았다. 장비에서는 문제가 발생하면 가장 간단히 확인 할 수 있는 것이 LED(상태를 나타내는 램프)이다. LED는 정상적이었고 달리 무엇이 문제인지 알 수가 없었다.
당시만해도 필자 역시 경험이 많지 않아 설마 케이블이 불량일거라는 생각은 하지도 못했다. 아무리 장비들을 확인해봐도 이상이 없어서 지푸라기라도 잡는 심정으로 확인해 본 것이 케이블. 확인 결과 건물과 백본 스위치(Backbone Switch)를 연결하는 케이블이 불량이라는 사실을 알 수 있었다. 케이블이 얼마나 중요한지 새삼 깨달을 수 있는 경험이었다.
꼭 불량이 아니더라도 케이블 때문에 생길 수 있는 문제는 참 많다. 여기에서는 먼저 우리가 많이 사용하는 케이블의 종류와 불량케이블을 확인할 수 있는 방법에 대해서 알아보자. 일반적으로 PC와 장비를 연결할 때에는 대부분 TP(Twisted-pair) 케이블을 사용한다. 우리말로는 ‘꼬인 선’ 정도로 풀이 된다.
TP 케이블은 다시 UTP와 STP 케이블로 구분된다. STP케이블은 잘라보면 전선에 절연체가 덥혀 있어 전기적인 특성을 많이 타지 않는 것이 특징이지만 가격이 비싸서 많이 사용되지는 않는다.
UTP는 Unshielded Twisted-pair의 약어로 STP(Shielded Twisted-pair)케이블과는 다르게 케이블을 잘랐을 때 따로 절연체(은박지)로 덥혀 있지 않은 케이블이다. 흔히 사용되는 UTP는 다시 1에서 6까지의 카테고리로 나뉜다.
카테고리를 나누는 기준은 케이블의 전송속도와 형태이다. 현재 LAN 환경에서는 대부분이 카테고리 5이상 사용하고 있다. <표 1>은 UTP 케이블의 규격을 나타난 것이다.
만약 자신의 랜 카드가 1Gbps를 지원하는 랜 카드이고 스위치 가 1Gbps를 지원 한다면 케이블은 카테고리 5-e 이상의 규격을 사용하여야 정상적인 속도를 제공받을 수 있다.

UTP케이블 다음으로 많이 사용되며 최근에 많은 주목을 받는 케이블은 광케이블이다. TP케이블은 100M 이상의 거리에서 사용하기 어렵다는 단점이 있지만 광케이블의 경우는 수 미터에서 수백 킬로미터까지 데이터전송에 제한이 없기 때문이다. 보통 백본 스위치, 워크그룹 스위치(Workgroup Switch)와 서버를 연결할 때는 광케이블을 사용한다. <표 2>는 케이블 커넥터의 일반적인 타입 종류들이다.
광케이블은 거리에 따라 멀티모드 케이블과 싱글 모도 케이블로 나뉜다. 멀티모드 케이블은 최대전송거리 2Km, 싱글 모드 케이블은 기본적으로 장비의 종류에 따라 전송거리를 제공하므로 전송거리가 2Km 이상 일 때 구성되는 케이블이다.
컴퓨터간 통신 에러의 주범 케이블
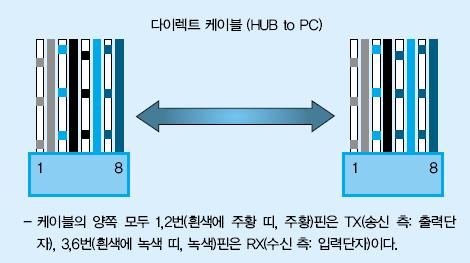
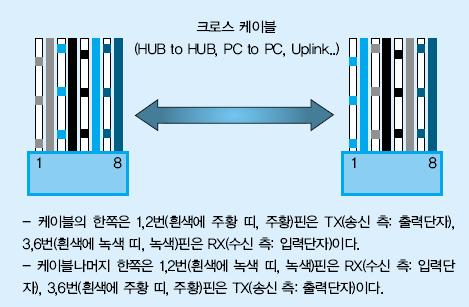
컴퓨터와 장비(Switch나 Hub)를 연결할 때는 <그림 1>와 같은 모양의 다이렉트 케이블(Direct cable)을 사용한다. 그런데 이 다이렉트 케이블을 컴퓨터와 컴퓨터를 연결하는 데에 사용하여 문제가 발생하는 경우가 종종 있다. 컴퓨터와 컴퓨터를 연결할 때에 다이렉트 케이블을 사용하면 네트워크를 구성할 수 없다.
컴퓨터와 컴퓨터를 연결해야 할 때에는 <그림 2>와 같은 모양의 크로스 케이블(Cross cable)을 사용해야 한다. 다이렉트 케이블과 크로스 케이블을 구분하는 가장 확실한 방법은 케이블의 양쪽 끝 모양을 확인하는 것이다.
케이블 양 끝의 선 순서가 같으면 다이렉트 케이블이고 그렇지 않으면 크로스 케이블이다. 또, 양 끝의 선 순서가 다르다고 무조건 제대로 된 크로스케이블이 아니며 <그림 2>처럼 1, 2, 3, 6 번 선의 순서가 제대로 배열되어 있어야 한다.

간혹 네트워크가 느려지는 원인으로 케이블 불량을 의심하기도 하는데, 케이블 탓에 네트워크가 느려지는 경우는 흔치 않다. 케이블에 문제가 있다면 아예 네트워크 접속 자체가 안 되는 탓이다.

만약, <그림 1> <그림 2>와 같이 적절한 케이블을 사용했는데도 네트워크 연결이 되지 않는다면 TP 케이블 테스터를 사용해서 케이블의 상태를 확인할 수 있다.
전파사 등에서 <화면 2>와 같은 모양의 TP 케이블 테스터(일명: 랜 테스터)를 구입한 뒤에 케이블 양 끝을 테스터에 꼽으면 케이블 상태를 확인할 수 있다. 테스트 결과 케이블의 상태가 좋지 않다면 케이블을 보수하는 대신 교체하는 편이 좋다.
광케이블을 사용하는데 접속이 불량일 때의 원인과 해결법
광케이블은 먼지나 구부러짐(bending)에 매우 민감하기 때문에 주로 이러한 원인이 트러블을 일으키게 된다. 광케이블의 가장 중요한 요소가 바로 빛의 세기(dB)인데 먼지나 구부러짐으로 인해 빛의 세기가 줄어들거나 단선을 유발하는 탓이다. 혹은 광케이블 연결에 사용하는 컨버터인 GBIC(GigaBit I/F Converter)의 불량이 비슷한 증상을 유발하기도 한다.

물론, 케이블의 빛의 세기가 무조건 높다고 좋은 것이 아니기에 적당한 세기(-3dB ~ -19dB)로 맞춰 주어야 한다. 광케이블을 사용하고 있는데 접속이 불량하거나 속도가 느려진다면 옵티컬 파워 미터(Optical Power meter)를 이용해서 빛의 세기를 측정한다.
일반적으로 dB 값이 너무 높을 경우 광 소자가 문제를 일으키게 되고, 너무 낮으면 접속이 되지 않는다. 옵티컬 파워 미터로 빛의 세기를 측정한 결과 빛이 너무 강하면 감쇄기를 사용해서 적정 수준으로 맞춘다. 빛의 세기가 너무 약할 때에는 해당 모듈이나 장비를 교체해야 한다. 일반적으로 너무 낮을 경우에는 장비 불량도 일부 있지만, 지빅(GBIC)이나 FX모듈(100M 광 모듈) 불량일 때가 많다.
일반적으로 네트워크에서 가장 흔히 접하는 도구가 바로 NIC(Network Interface Card) 즉 랜 카드이다. 도스 시절이나 윈도우의 초기처럼 일일이 시스템 파일을 만지고 드라이브를 설치할 필요 없이 윈도우를 설치할 때 자동으로 인식되는 랜 카드.
본체에 연결만 해 두면 대부분 별다른 문제없이 잘 돌아가기 때문에 별로 신경이 가지 않는 랜 카드지만, 한번 골을 냈다 하면 대형 사고를 치는 도구이기도 하다. 랜 카드가 일으키는 장애와 해결방법에 대해 알아보자.
랜 카드도 대형장애의 원인
몇 달 전 필자가 관리하는 네트워크 장비 중에 중요한 스위치가 다운된 적이 있다. 사실 네트워크 관리자라 하더라도 이렇게 느닷없이 스위치가 다운되는 원인을 찾기란 쉽지 않은 일이다. 많은 컴퓨터 사용자가 그러하듯 원인을 파악하기 어려운 문제가 발생할 경우 네트워크 관리자들도 빠른 복구를 위해 해당 장비를 리부팅하는 방법을 사용한다.
필자도 가장 빠르고 확실한 해결을 위해 이 방법을 택했지만 같은 문제가 일주일 동안 지속되니 뭔가 대책이 필요했다. 네트워크를 트래픽을 분석해 보니 서버의 랜 카드가 불량 트래픽을 발생시켜서 전체 스위치에 영향을 주고 있었다.
우선 해당 시간에 백본 라우터는 EIGRP(라우팅 프로토콜의 하나)로 구성되었는데 해당 시간에 EIGRP로 이웃(Neighbor)을 맺은 라우터와 단절현상이 발생되었다. 또 백본 라우터에서 다음과 같은 메시지를 나타내며 EIGIP를 재실행한다는 메시지를 보냈다.
<백본 라우터의 로그>
%DUAL-5-NBRCHANGE: IP-EIGRP 11: Neighbor 172.27.1.3 (FastEthernet0/0/0) is down: peer restarted
%DUAL-5-NBRCHANGE: IP-EIGRP 11: Neighbor 172.27.1.3 (FastEthernet0/0/0) is up: new adjacency
그리고 스위치에서는 특정 MAC에서 플래핑(flapping)이 발생하여 지속적으로 업/다운을 발생하며 다음 메시지를 로그서버로 보냈다.
<스위치의 로그>
%C4K_EBM-4-HOSTFLAPPING: Host 00:03:2E:05:00:00 in vlan 1 is flapping between port Gi2/15 and port Gi6/44
%C4K_EBM-4-HOSTFLAPPING: Host 00:03:2E:05:00:00 in vlan 1 is flapping between port Gi2/15 and port Gi6/44
해당 MAC을 확인해 본 결과 최근에 신규로 개발을 위해서 도입한 NT서버라는 것을 확인했다. 이후에 랜 카드를 변경하여 장애를 복구할 수 있었다. 좀 더 빨리 원인을 알았더라면 대형장애를 예방할 수 있었던 사례였다.
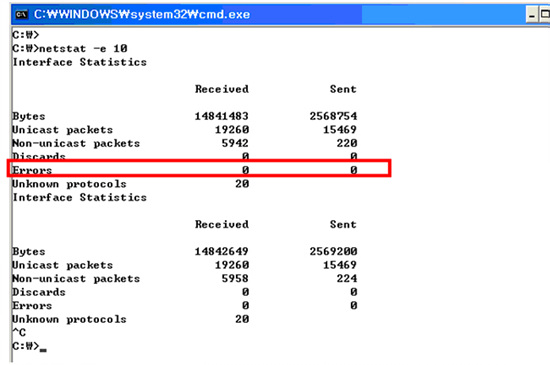
만약 자신의 랜 카드에 문제가 있다고 의심이 된다면 <화면 6>처럼 도스 모드에서 ‘netstat –e’ 라는 명령어를 사용하면 네트워크의 실시간으로 모니터링을 할 수 있다. 특히 빨간색 네모에서 error가 자주 발생한다면 랜 카드나 PC와 접속되어 있는 장비를 의심해 볼 만하다. 명령어 뒤쪽에 10은 10초마다 패킷 상태를 표시하라는 의미이다.
Unknown protocols는 윈도우에서 인식하지 못하는 프로토콜을 사용하는 패킷을 말한다. 정상적인 패킷이지만 윈도우에서 인식하지 못하는 경우도 있으니 이것만으로 컴퓨터나 랜 카드가 불량이라고 의심하기에는 부족하다.
바이러스나 스파이웨어의 경우 패킷을 유발할 가능성이 높은 만큼 백신프로그램이나, 스파이웨어 제거프로그램을 자주 실행해서 예방하는 것이 중요하다. 그리고 인터넷을 사용하다가 갑자기 속도가 느려지거나, 혹은 네트워크에 문제가 발생하면 가장 먼저 자신의 컴퓨터 상태를 점검해야 한다.
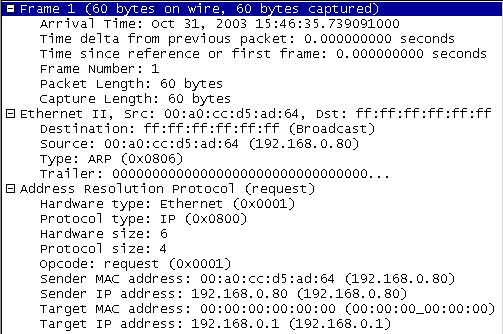
편지나 메일을 주고 받기 위해 주소가 필요하듯 서로 다른 네트워크 장비가 통신을 할 때에도 주소를 이용한다. 그 중 가장 대표적인 주소가 바로 MAC 주소와 IP 주소이다. 랜 카드를 포함해서 모든 통신장비들은 고유의 주소를 가지는데 이런 주소를 MAC(Media Access Control) 주소라고 부른다.
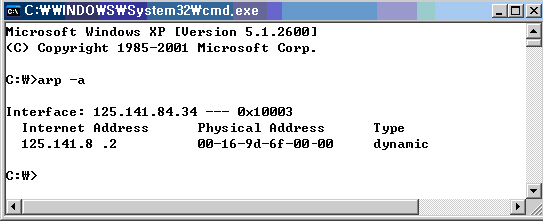
자신의 컴퓨터에서 커맨드 창을 하나 열고 ‘arp –a’ 라고 입력하면 현재 자신의 MAC 주소를 알 수 있다. <화면 7>은 arp –a를 실행했을 때 자신의 MAC 및 IP를 확인할 수 있다.
<화면 7>에 표시되어 있는 ‘00-16-9d-6f-00-00’이 MAC 주소 이다. MAC 주소는 총 48bit로 되어 있고 앞의 24bit (00-16-9d)는 제조회사 코드이고 나머지는 24bit(6f-00-00 )는 일련번호이다. 먼저 통신을 하기 위해서는 서로의 MAC 정보를 알아야 한다. 일반적으로 IP주소를 가지고 통신하고 있는 것으로 알고 있는데, IP주소(논리적 주소)로만 통신이 가능하지 않다.
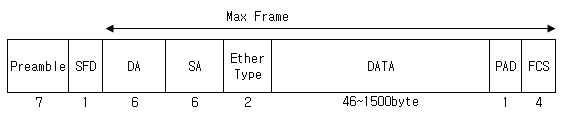
보통 패킷은 레이어 3계층인 네트워크 계층에서 다룬다. 이 패킷들이 인캡슐레이션(encapsulation)과정을 거친 뒤에 레이어 2로 내려오는데 이렇게 내려온 패킷을 프레임이라고 부른다. L2 프레임의 포맷은 아래 <그림 3>과 같다.
- Preamble: 수신 클럭을 추출하여 송수신 속도를 맞추는 동기를 제공함.
- SFD(Starting Frame Delimiter): 다음 바이트 열이 프레임의 시작을 알림.
- DA(Destination Address): 목적지 MAC주소
- SA(Source Address): 송신 측 MAC주소, - EtherType: MAC 프레임 다음의 데이터 부분에 상위 프로토콜의 종류를 표시함.
- Data: 상위 프로토콜이 위치. 최대 허용길이(MTU)는 1500바이트임. DA부터 FCS까지 전체길이가 64바이트 이상이어야 한다는 규정을 준수해야 함.
- 패딩: 최소길이 규정을 만족하지 못할 경우 '0'으로 채움.
- FCS: 프리앰블과 SFD를 제외한 MAC프레임의 비트열의 에러를 검사함.
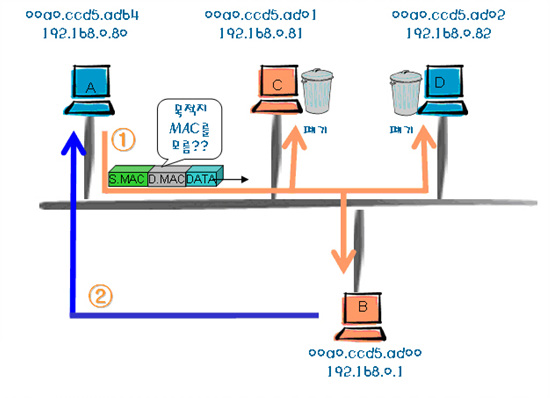
<그림 4>에서도 알 수 있듯이 통신 해야 할 목적지인 MAC 주소를 바로 알 수 없다. 따라서 IP 주소를 MAC 주소로 변환해 주는 과정이 있으며 이를 ARP(Address Resolution Protocol)라고 한다. ARP는 주소를 변환해주는 프로토콜이다. 변환이라기 보다는 알아내는 프로토콜이라는 표현이 더 적당할 듯하다. <그림 4>를 통해서 ARP의 동작 과정을 이해해 보자.
① 호스트 A에서 호스트 B로 프레임을 보내려 한다.
- 호스트 A는 호스트 B의 L2 주소를 알기 위해서 같은 네트워크 내의 모든 노드에게 ARP 리퀘스트 패킷을 보낸다.
- 호스트 C와 D는 ARP 리퀘스트를 받았지만 자신의 IP주소에 관한 내용이 아니므로 무시한다.
② 호스트 B는 ARP 리퀘스트를 받고 자신의 IP주소에 맞는 내용이므로 호스트 A에게 자신의 MAC 주소를 담은 ARP 리스폰스를 보냄으로 응답한다.
- 호스트 A는 호스트 B로부터 온 ARP 리스폰스를 받고 호스트 B의 L2 주소를 알게 되고 ARP 테이블에 저장한다.
이제 호스트 A는 호스트 B로 L2(MAC) 주소를 사용해서 프레임을 전송한다.
- 다른 패킷을 보내는 경우 호스트 A는 자신에게 있는 ARP 테이블을 사용하기 때문에 ARP lookup(2단계~5단계)을 생략할 수 있다.
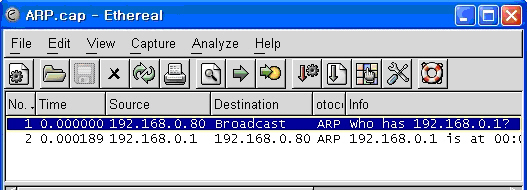
<화면 8>에서 일어나는 일련의 과정을 이더리얼(Ethereal)라는 패킷 분석 프로그램으로 캡처하면 <화면 8>과 같은 결과를 얻을 수 있다. 우선 자신을 제외한 모든 호스트의 MAC을 모르고 있기 때문에 ARP 리퀘스트 패킷을 모든 호스트로 보낸다.
이 패킷 형태는 브로드캐스트(Broadcast)라고 하는데 이런 브로드캐스트 패킷은 네트워크의 입장에서는 줄여야 하는 패킷이고, 가끔은 장애의 원인이 되기도 한다.
<화면 9>의 패킷 예를 자세히 살펴보면 Target MAC address 라는 부분이 00:00:00:00:00:00 이라고 되어 있다. 이것은 모든 호스트로 보낸다는 의미이다. 이렇게 습득한 MAC 정보는 자신의 ARP 테이블에 저장하고 일정시간 동안 관리한다.
정리하자면 논리적 주소인 IP 주소는 사용하기 편리하지만 실제로 통신에 사용되는 주소는 물리적 주소인 MAC이다. 즉 ‘MAC 주소 = 부여한 IP주소’라는 식이 만들어지고 실제로는 MAC 주소가 통신에서 사용된다는 사실이다.
집에서 인터넷을 사용할 때 사용하는 공유기 역시 여기에서 설명할 허브의 한 종류이다. 이 허브는 랜의 중심에 해당하는 장비이다. 간단히 말하면 여러 대의 컴퓨터를 연결하고 싶은데 중간에 연결 시켜줄 수 있는 매개체가 필요할 때 사용하는 장비이다. 일반적으로 네트워크 토플로지(네트워크형태)에서 <그림 5>과 같은 스타형 토플로 방식으로 랜을 구성한다면 무조건 허브이나 스위치가 필요하다.
스타형은 말 그대로 백본을 중심으로 한 가닥씩 라인을 뻗어 네트워크를 구성하는 것이다. 스타형은 한 에지 단에 장애가 발생하더라도 전체 네트워크에 영향을 덜 미친다는 장점이 있다. 반면에 백본에 장애가 발생하면 모든 네트워크가 중단된다.
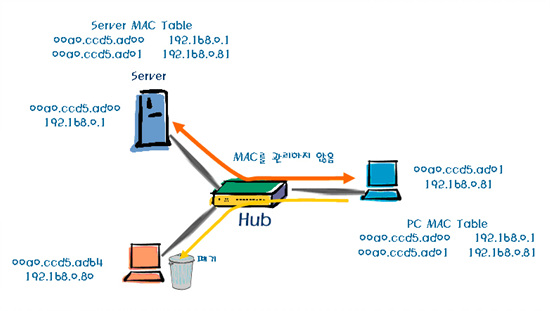
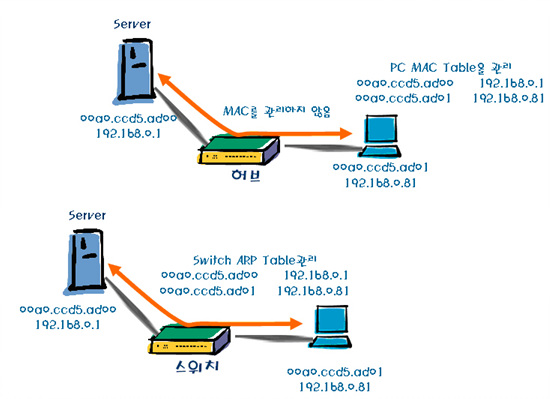
허브는 매우 단순한 구조로 만들어져 있으며 그만큼 장애에도 취약하다. 우선 허브는 중앙에 집중되어 있는 장비지만, 연결되어 있는 호스트의 MAC을 관리하지 않는다.
<그림 6>에서 허브는 연결되어 있는 포트를 통해 모든 포트로 해당 패킷을 보내게 된다. 그렇게 되면 아래 호스트는 자신과 관련 없는 패킷이기 때문에 해당 패킷을 폐기(Drop)한다. 서버와 통신하는 컴퓨터는 자신에게 온 데이터라는 것을 알고 바로 처리한다. 그리고 각각의 컴퓨터에서 MAC 주소 테이블을 관리하게 된다.
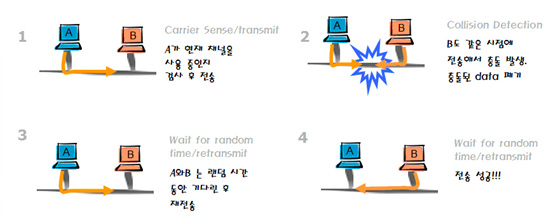
일반적으로 이더넷(Ethernet) 환경에서 가장 큰 특징 중에는 CSMA/CD라는 액세스 메소드(Access Method)를 이용한다.
<그림 7>은 CSMA/CD방식을 나타낸 것이다. 이는 하나의 통로를 여러 패킷이 동시에 사용하면서 생길 수 있는 충돌을 예방하기 위한 통신방식이다. 패킷을 전송하기 전에 이미 통로를 사용하고 있는 패킷이 있는지 확인한 뒤에 먼저 사용중인 패킷의 전송이 끝난 뒤에 새 패킷을 전달하는 방식으로 패킷 간의 충돌을 예방한다.
그럼, 동시에 둘 이상의 곳에서 사용중인 패킷이 없음을 확인하고 동시에 패킷을 전송하면 어떻게 될까? 당연히 각 패킷이 충돌을 하게 되는데 이러한 현상을 콜리전(Collision)이라고 한다. 콜리전은 CSMA/CD 방식에서 필연적으로 발생하며 콜리전이 발생할 수 있는 범위를 콜리전 도메인이라고 부른다.
보통 허브는 하나의 콜리전 도메인이라서 한 순간에 한 호스트만 통신한다. 다른 PC들은 통신이 끝나기를 기다려야 한다. 허브를 사용하면 네트워크가 느려진다고 느껴지는 이유가 바로 여기에 있으며, 이는 허브가 가지고 있는 원천적인 한계이다.
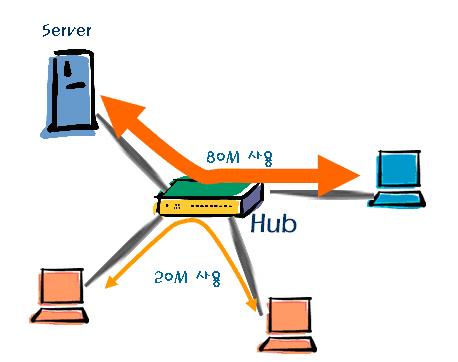
일반적으로 허브는 셰어드(Shared)방식을 사용한다. 이 말은 <그림 8>처럼 100Mbps 허브면 100Mbps를 가지고 모든 연결된 컴퓨터가 나누어 사용하게 된다는 뜻이다. 예를 들어 그림에서 허브에 연결된 세 대의 컴퓨터와 한 대의 서버가 100Mbps 허브에 연결되어 있다면 일반적을 25Mbps정도의 속도를 나누어 쓰고 있다고 생각하면 된다.
그런데 이 네 대 중 먼저 서버와 컴퓨터간에 80Mbps를 점유하여 사용하던 컴퓨터가 있다면 이 컴퓨터의 네트워크가 끝날 때까지 남은 20Mbps로 나머지 컴퓨터들이 사용해야 한다. 그렇기 때문에 누군가 대용량의 파일을 다운로드 받고 있으면 다른 컴퓨터의 네트워크 속도가 저하되기도 하는 것이다.
허브의 콜리전 발생 상태 확인하기
사용중인 허브에 얼마나 많은 콜리전이 발생하는지 가장 빠르게 확인할 수 있는 방법은 허브에 달린 LED를 확인하는 것이다. 허브의 LED 중에는 콜리전 상태를 나타내는 LED가 있는데, 콜리전이 많으면 이 LED가 많이 깜박인다.
콜리전 발생으로 생기는 네트워크 속도 저하를 줄이기 위해 사용할 수 있는 방법이 바로 뒤에서 설명하게 될 스위치이다. 만약 자신의 회사에서 허브를 사용하고 있는데 속도 때문에 골치라면 허브를 스위치로 교체하여 문제를 줄일 수 있다.
스위치와 허브의 모양은 거의 비슷하다. 실제로 보통 사람들이라면 겉모습만 보고 둘을 구분하기 조차 어려운 일이다. 스위치와 허브의 가장 큰 차이는 MAC 주소 관리 능력이다. 스위치는 MAC 주소 테이블을 가지고 있기 때문이다.
<그림 9>에서처럼 허브는 프레임을 전송하기 위해 브로드캐스트를 날리고 관련 ARP 테이블을 컴퓨터에서 관리를 하게 한다. 따라서 컴퓨터에서 통신할 상대편의 MAC 주소가 없다면 매번 날려서 상대편 MAC 주소를 인지하는 수 밖에 없다. 반면 스위치는 테이블에 MAC을 획득하기 위해 플로딩(Flooding)이라는 과정을 거친다. 이렇게 획득한 MAC 주소를 일정한 버퍼에 담아 두었다가 목적지의 MAC 주소가 없을 때 사용한다.
따라서 이렇게 함으로써 CSMA/CD의 문제점인 프레임충돌(콜리전)을 줄일 수 있는 장점이 있다. 또한 불필요한 브로드캐스트를 감소시킬 수 있다. 더불어 스위치에서 VLAN을 이용하여 브로드캐스트 프레임으로 인한 성능저하도 줄일 수 있다.
IP 충돌 발생시 스위치에서 해당 포트를 알아내는 방법
센터에서 근무를 하다 보면 IP 충돌과 관련된 문제가 흔히 발생한다. 필자가 현재 일하고 있는 곳에서는 DHCP에 의해서 IP를 받아 오도록 되어 있는데, 간혹 외부인을 방문해서 임의로 IP를 설정하여 문제가 발생하는 경우가 있다(독자들 중에도 이런 경험이 있을 것이다). 이런 경우 임의로 IP를 설정한 유저를 찾으면 되는데 어떻게 찾을지는 난감하다.
시스코의 스위치를 기준으로 임의로 IP 주소를 설정한 포트를 찾는 방법에 대해 알아보자. 일반적으로 IP가 충돌하면 시스코 스위치가 다음과 같이 메시지를 표시한다. 시스코 스위치에서는 IP 충돌 발생 시 duplicate address라는 메시지를 보여준다.
%IP-4-DUPADDR: Duplicate address 192.168.0.1 on Ethernet1/0, sourced by 0000.5e00.0000
명령어 “sh arp”로 해당 IP를 확인한다.
Switch#show arp
Protocol Address Age (min) Hardware Addr Type Interface
Internet 192.168.0.2 34 0003.bab1.0000 ARPA Vlan1
Internet 192.168.0.1 163 0000.5e00.0000 ARPA Vlan1
이런 메시지가 표시되면 ‘192.168.0.1’이라는 IP를 사용하는 사람을 찾으면 된다. 그 MAC 주소가 0000.5e00.0000 이다.
여기까지 찾았다면 이 MAC이 어느 포트에서 올라오는지를 확인하면 된다. ‘sh mac-address-table’ 이라는 명령어를 이용하면 간단히 해당 포트를 찾을 수 있다.
Switch#sh mac-address-table
Mac Address Table
-------------------------------------------
Vlan Mac Address Type Ports
---- ----------- -------- -----
1 0000.0c07.ac34 DYNAMIC Fa0/1
1 0000.5e00.0101 DYNAMIC Fa0/2
1 0000.f091.cfac DYNAMIC Fa0/3
1 0000.5e00.0000 DYNAMIC Fa0/8
간단히 해당 MAC 포트에 올라오는 포트가 Fa0/8이라는 것을 알 수 있다. 관련하여 포트를 disable 하던지 아니면 IP변경을 요청하면 된다.
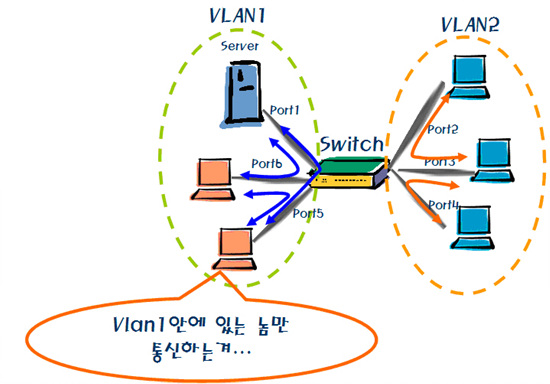
VLAN(Virtual LAN)이란 한마디로 논리적으로 브로드캐스트 도메인을 나누는 것이다. 하드디스크에서 파티션을 나누어 하나의 하드디스크를 둘 이상으로 나누어 사용하는 것과 비슷하다고 생각하면 쉽게 이해될 것이다. VLAN도 물리적으로 하나의 장비에서 통신을 해야 하는 여러 그룹으로 논리적으로 묶어서 나누는 것이다. 이렇게 나눠진 VLAN끼리는 서로 브로드캐스트를 보내지 않는다.
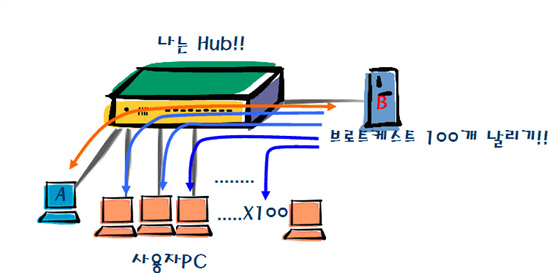
왜 이렇게 복잡한 작업을 해야 할까? 앞에서 설명한 허브를 생각해보자. <그림 10>처럼 100 포트 허브가 있다고 생각해보자. A와 B가 통신하려면 서로의 MAC 주소를 확인하기 위해 브로드캐스트를 보내야 할 것이다. 그런데 연결된 컴퓨터가 많다 보니 A와 B가 통신하려면 100개의 브로드캐스트를 날려야 한다.
그러면 100개의 호스트에서 각각 브로트케스트를 날리면 어떻게 되겠는가? 각각 컴퓨터가 모두 통신한다고 생각하면 10,000개(100 대의 컴퓨터 × 100 개의 브로드캐스트)의 어머어머한 브로트케스트가 발생하는 셈이다. 그런데 호스트가 100개가 아니라 5,000개면 어떻게 될까? 호스트의 수가 늘면 늘수록 네트워크 자원의 소모가 많아져 네트워크의 속도를 저하시키는 원인이 될 것이다.
이런 문제를 해결하기 위해서 나온 것이 VLAN이다. <그림 11>를 보면 스위치는 물리적으로 한 대인데 VLAN1과 VLAN2로 나누어 Port1, 6, 5끼리 통신을 하고 Port2, 3, 4번끼리 통신을 한다. 이렇게 함으로 VLAN1에 포함되어 있는 패킷이 VLAN2로 넘어가지 않도록 한다. 그림처럼 몇 대 되지 않는 환경에서 VLAN을 나눌 필요가 없겠지만, 호스트의 수가 많을 경우 사용 그룹별로 묶어서 VLAN을 설정해 주는 것 만으로도 네트워크의 속도를 높일 수 있다.
이렇게 VLAN을 나누는 기준은 몇 가지가 있다. MAC이나 Port등으로 VLAN을 나눌 수 있지만, Port VLAN을 가장 많이 사용된다. 브로드캐스트 감소로 네트워크 트래픽 또한 감소되며 그 이외에도 VLAN은 보안 측면에서도 중요한 역할을 한다. 예전에 ‘모 아파트에 진출한 통신회사에서 기존의 xDSL방식이 아닌 이더넷 방식으로 서비스를 제공하였다’는 내용의 뉴스가 보도된 적이 있다.
그런데 이 아파트 사람들의 윈도우에서 ‘네트워크 환경’을 클릭하면 이웃집 컴퓨터까지 다 보여주어서 개인정보가 유출된다는 내용의 뉴스였다. 이를 해결할 수 있었던 것이 VLAN이다. 간혹 같은 장비에 PC나 서버를 연결하였는데 링크나 케이블은 정상인데도 불구하고 통신이 되지 않는다면 우선 장비에서 VLAN이 설정되었는지를 확인해야 한다. 앞서 설명한 것처럼 동일 VLAN에서는 통신이 가능하지만 서로 다른 장비에서 같은 VLAN끼리는 통신이 되지 않는다.
이처럼 VLAN은 브로트케스트를 감소시키는 것은 물론 보안에도 중요한 역할을 한다. VLAN 생성 및 삭제, 포트 할당하는 방법은 다음과(시스코 스위치 기준) 같다. 일반적으로 벤더(원천업체)마다 그 방법은 다르다.
- VLAN 생성
C6509(config)#vlan 2 <- VLAN 2 생성
- 해당 인터페이스 VLAN설정
C6509(config)#interface gi1/1
C6509(config-if)#switchport <- Switch Port로 변경
C6509(config-if)#switchport mode access <- access 포트로 지정
C6509(config-if)#switchport access vlan 2 <- vlan 2 에 할당 설정
C6509#sh vlan id 2 <- VLAN 확인방법
VLAN Name Status Ports
2 VLAN2 active Gi1/1
- VLAN 삭제
C6509(config)#no vlan 2 <- VLAN2 삭제 (삭제 시에는 해당 VLAN에 할당된 인터페이스가 없어야 함)
브로드캐스트 스톰(Broadcast Storm) 해결하기
브로드캐스트가 자주 일어나면 이를 처리하기 위해 장비에 부하가 발생한다. 또 각 노드(사용자)에서의 처리가 실행되지 않아 네트워크 전체가 다운되기도 하는데 이런 경우를 브로드캐스트 스톰(Broadcast storm)이라고 말한다. 브로드캐스트 스톰은 프로토콜의 버전 차이에 의해서 발생하는 경우가 많다.
TCP/IP에서는 4.3 BSD와 4.2 BSD의 혼재, Appletalk Phase I과 Phase II의 혼재 등이 그 예이다. 브로드캐스트의 패킷은 보낼 곳의 주소를 가지고 있다. 때문에 네트워크 장애가 브로드캐스트에 의한 것인지 아닌지는 보통 스니퍼와 같은 분석 툴을 이용하여 패킷의 어드레스를 조사해 보면 알 수 있다.
최근에 나오는 스위치들은 패킷을 분류하여 컨트롤할 수 있는 기능이 있으며, 액세스 단의 시스코 스위치는 ‘storm-control’ 이라는 명령을 이용해 포트에 과도한 브로드캐스트가 발생하면 자동 다운되도록 설정할 수 있다.
다음은 Strorm-control을 적용한 것으로 70%가 넘는 브로드캐스트가 해당포트에 발생하면 자동으로 포트가 다운되도록 설정한 예이다. 참고로 해당 포트 enable(활성화)은 자동으로 되지 않고, 관리자가 직접 입력 해야 한다. 옵션으로 포트를 다운시킬 수도 있지만, Trap을 보내어 로그 서버나 로그에서 확인할 수도 있다.
Switch(config-if)#storm-control broadcast (multicast, unicast) level 70 (퍼센트)
Switch(config-if)#storm-control action shutdown (trap)
네트워크에서 가장 빈번하게 발생하는 문제 중 하나는 프레임이나 패킷에서 에러가 발생하는 경우이다. 이때 발생한 에러를 스위치에서 확인하는 방법과 에러의 종류들에 대해 알아보자. 다음은 스위치에서 Show interface를 확인 하는 명령어를 실행 한 것이다.
Switch#show interface fa0/1
FastEthernet0/1 is up, line protocol is up (connected)
Hardware is Fast Ethernet, address is 000d.bdf0.8401 (bia 000d.bdf0.0000)
Full-duplex, 100Mb/s
----중략------
①3684426280 packets input, 488947651 bytes, 0 no buffer
Received 82551896 broadcasts (0 multicast)
0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 20 ignored
0 watchdog, 40251954 multicast, 0 pause input
0 input packets with dribble condition detected
②3120267351 packets output, 124174218 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 PAUSE output
0 output buffer failures, 0 output buffers swapped out
Show Interface 명령은 간단한 명령어지만 많은 내용을 포함하고 있다. 아마도 하나의 명령어로 많은 부분을 파악할 수 있을 것이다. ①부분은 서버에서 스위치로 입력된 패킷을 나타내고, ②부분은 스위치에서 서버나 기타 접속되어 있는 장비로 나가는 패킷의 개수다. 일반적으로 서버나 장비가 정상적으로 연결되면 FastEthernet0/1 is up, line protocol is up 인터페이스와 라인프로토콜이 모두가 UP으로 되어 있다.
정상적인 패킷의 경우는 64k이상 ~ 1,518k미만이 정상적이다. 이 이외의 패킷이 들어오면 스위치에서는 해당 패킷을 파기하는데 runts 64k 미만의 패킷 수이고, giants는 1500k 이상 패킷을 말한다. 이런 패킷들은 대부분 폐기한다. Throttles는 처리범위 이상으로 유입되는 패킷의 개수를 말한다.
그리고 input error는 소스에서 만들어진 패킷이 불량인 경우인데, 이 경우에는 연결된 서버의 랜 카드나 장비가 불량인 경우가 많다. 그리고 CRC나 Frame은 프레임에서의 에러를 나타내고 위에서 설명한 Duplex나 회선에 문제가 발생할 때 관련 카운터가 증가한다.
장비는 버퍼를 가지고 있는데, 버퍼를 초과하는 패킷이 들어오면 Overrun의 카운터가 증가한다. Ignored는 버퍼에서 처리 못하는 패킷을 폐기할 때 발생한다.
Output error가 발생할 때는 해당 스위치가 에러가 발생할 경우가 많다. Duplex 모드 등 이상이 없는데도 에러가 증가한다면 해당장비를 교체하는 것이 현명하다. Collisions은 앞서 설명한 부분이라 생략하겠다. interface resets의 경우에는 해당 포트가 리셋 될 때 인데, 보통 과도한 패킷이 들어오거나 하드웨어가 불량일 경우 발생한다.
Babbles 1518 바이트 이상의 프레임이며 점보프레임과 같은 의미이다. late collision은 CSMA/CD에서 규정한 시간 내에 프레임을 전송하지 못하고 전송이 지연되는 것을 의미한다. 일반적으로 UTP케이블의 사용길이는 100m데, 이것보다 긴 케이블을 사용하거나, 다음에 설명할 듀플렉스가 안 맞을 경우 발생한다.
스위치와 서버를 연결한 뒤에 ping이 빠지거나, 속도가 느려질 경우
앞에서 ‘Full-duplex, 100Mb/s’ 부분은 듀플렉스 모드와 스피드를 나타낸다. 듀플렉스 모드가 mismatch일 때는 CRC 에러나 Runts 패킷이 많이 발생한다. 서버나 기타 통신장비가 스위치와 통신할 때 에러가 발생하는 원인 중 가장 큰 비중을 차지하는 것이 바로 이 듀플렉스 문제이다.
듀플렉스는 시스템이 서로 통신할 때 송신과 수신이 어떤 형식으로 이루어 지는 지에 대한 일종의 모드이다. 정보통신학개론 등의 책에 빠지지 않고 등장하는 메뉴인 듀플렉스는 단 방향 통신(Simplex), 반 이중방식(Half Duplex), 전 이중방식 (Full Duplex)의 세 가지 방식으로 나뉜다.
아주 오래된 장비라면 반 이중방식을 최근에 설비된 장비라면 대부분 전 이중방식이 적용되어 있다고 보면 된다. 전 이중방식으로 설비된 100M장비의 Throughput은 200Mbps가 된다.
듀플렉스는 통신하는 기기 즉 서버와 같은 시스템의 네트워크 인터페이스, 스위치 포트들 또는 스위치 포트와 라우터 인터페이스간에 서로 일치하도록 설정해야 한다. 100/10 랜 카드와 스위치의 경우 상호 오토네고네션(auto-negotiation)을 수행하여 속도와 듀플렉스 모드가 자동적으로 설정된다.
반면 장비간 오토네고네션 프로토콜의 차이로 인해 제대로 연결되지 않을 수 있다. 따라서, 100Mbps 속도를 지원하고 전 이중방식을 지원하는 장비들 간에는 오토네고네션 기능을 disable하고 100Mbps-Full Duplex로 fix하여 운영하는 것이 좋다. 듀플렉스 모드에는 auto, ull, half모드가 있으며, 속도는 지원하는 포트에 따라 10~1000M가 있다. 다음은 시스코 스위치에서 듀플렉스 및 스피드를 포트에 설정하는 방법이다.
Switch(config-if)#speed 100
Switch (config-if)#duplex full
이미 알아본 것처럼 VLAN이란 하나의 스위치를 둘 이상의 스위치인 것처럼 논리적으로 분할하여 사용하는 것이다. 그렇다면 둘 이상의 스위치에 서로 같은 VLAN을 설정하여 공유해야 할 때는 어떻게 하면 될까? 이번에는 서로 다른 스위치의 VLAN을 동일하게 설정하여 연결하는 방법에 대해 알아보자.
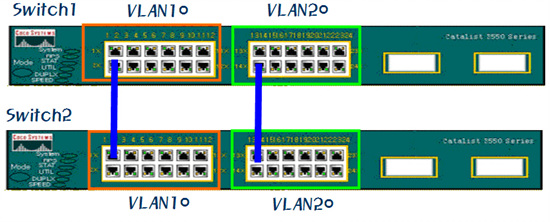
서로 다른 스위치의 VLAN이 통신하도록 설정하는 방법에는 두 가지가 있다. 하나는 라우팅이고 다른 하나가 트렁킹(Trunking)이다. 라우팅에 관해서는 3부에서 자세히 다루고 있기 때문에 여기에서는 생략한다. <그림 12>와 같은 네트워크가 있다면 스위치 1과 스위치 2에 각각 설정되어 있는 VLAN1을 링크하고 스위치 1과 2에 설정되어 있는 VLAN2를 링크로 연결해 주면 된다.
간단한 듯 보이지만 사실 이 방법은 아주 불편할 수도 있다. 예를 들어 서로 다른 두 개의 스위치에 설정되어 있는 VLAN의 종류가 100 가지라면 100 개의 링크가 필요한 탓이다. 이렇게 되면 링크의 수가 너무 많아지고 또 포트 낭비도 심해진다.
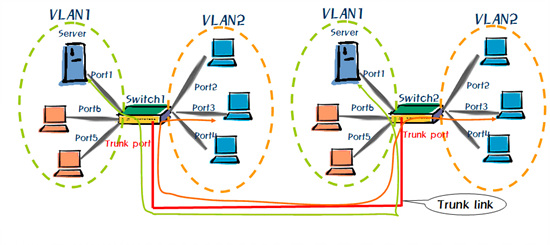
이런 문제를 해결하기 위해 착안된 것이 바로 링크를 통해 VLAN 정보를 주고 받는 VLAN 트렁킹이다. <그림 12>를 보면 스위치1과 2간에 링크는 하나지만 그 링크를 통해서 VLAN 정보가 넘어다니며 각각의 VLAN들이 통신할 수 있게 된다.
이처럼 VLAN 정보를 송수신할 수 있는 포트를 트렁크(Trunk)라고 부른다. 또 <그림 13>와 같이 트렁크 포트를 통해 통신하기 위해 VLAN 정보를 추가하는 것을 태깅(Tagging)이라고 한다.
태깅을 하기 위해 ISL(Inter Switch Link)와 IEEE 802.1q 방식을 주로 사용한다 있다. ISL는 시스코에서만 사용하는 것이고, IEEE 802.1q는 국제표준이다. IEEE 802.1Q는 tag-based VLAN이 Bridge를 거쳐가는 프레임의 vlan membership을 확인하기 위해 MAC header 내에 특별한 태그를 이용한다.
이 태그는 VLAN과 QoS priority의 식별에 사용된다. Vlan ID는 특정 VLAN과 프레임을 결합하여 네트워크를 거쳐가는 프레임에 대한 정보를 스위치에 제공한다.
태그드 프레임(Tagged frame)은 언태그드 프레임(Untagged frame)보다 4byte가 더 길고, 이는 2byte의 TPID(Tag Protocol Identifier)와 2byte의 TCI(Tag Control Information)을 포함한다. 이에 반해 ISL은 데이터 프레임의 양쪽 끝에 각각 26 octet의 ISL header와 4 octet의 CRC를 더한다. 이를 더블 태깅(double-tagging) 혹은 투 레벨 태깅 인캡슐레이션(two-level tagging encapsulation)이라고 한다. 다음은 시스코 스위치에서의 트렁크 설정에 대한 설명이다.
Switch(config)#interface Fa0/1
Switch(config-if)#switchport trunk encapsulation dot1q or isl <- Encapsulation방식 설정
Switch(config-if)#switchport mode trunk <- 해당포트 Trunk 포트로 설정
Switch(config-if)#switchport trunk allowed vlan 10,20 <- 트렁크포트로 허용할 VLAN
Switch#show interface trunk <- 트렁크포트 확인 시 명령어
Port Vlans allowed on trunk
Fa0/1 10,20
네이티브 VLAN이 서로 다를 경우에 문제점
모든 스위치에는 네이티브(Native) VLAN 이라는 것이 있다. 트렁크 포트나 액세스 포트를 제거 했을 때 돌아가는 VLAN을 네이티브 VLAN이라 한다. 일반적으로 시스코 스위치에서는 VLAN 1이 네이티브 VLAN이다. 제품을 구입해서 콘솔에 연결했을 때 최초 VLAN이 네이티브 VLAN인 것을 알 수 있다.
앞서 설명한 것처럼 802.1q의 경우 트렁크 구간이 기본적으로 VLAN 1로 인식되므로, 트렁크 구간으로 특정한 VLAN ID가 설정되어 있지 않은 데이터(Untagged Frame)가 들어오면 자동으로 VLAN 1로 인식된다. 이렇게 해서 두 스위치간의 트렁킹을 설정했을 때, 언태그드 프레임을 처리하기 위해 802.1에서는 네이티브 VLAN으로 처리하는 것이다.
반면에 ISL은 네이티브 VLAN이란 개념 자체를 가지지 않는다. 다시 말해 ISL에서는 네이티브 VLAN이 넘어가지 않는다.
앞에 설명한 것처럼 ISL은 네이티브 VLAN이 넘어가지 않는다. 802.1q에서만 네이티브 VLAN넘어간다.
일반적으로 VLAN1이 네이티브 VLAN인데 만약 한 스위치는 VLAN1이 네이티브이고, 다른 스위치는 VLAN2가 네이티브라고 가정해보자. 한마디로 네이티브 VLAN이 서로 다를 경우에는 어떻게 될까? 당연히 네이티브 VLAN이 넘어가지 않고 미스매치(mismatch)되기 때문에 해당 로그를 남긴다.
이럴 경우에는 네이티브 VLAN을 변경해 주어야 한다. CatOS에서는 트렁크를 설정하기 전에 set vlan으로 네이티브 VLAN을 설정한다. IOS에서는 switch port trunk native vlan 커맨드로 네이티브 VLAN을 설정한다.
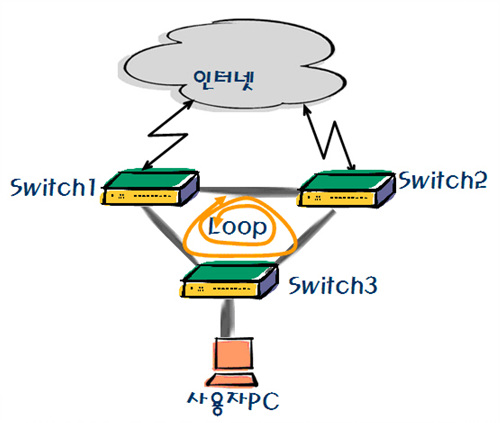
스위치를 사용하면서 가장 흔하게 발생하는 문제 중 하나는 루프(loop)이다. 루프는 단일경로에서는 거의 발생하지 않으며 이중화 구성 등 복잡한 구조의 네트워크에서 주로 발생한다.
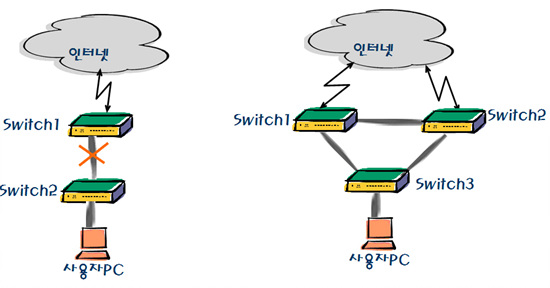
<그림 14>의 왼쪽 그림은 단일 경로로 연결된 네트워크이다. 사용자가 인터넷을 사용하면서 경유하는 경로는 ‘스위치 2->스위치1->인터넷’ 순으로 가는 방법뿐이다. 이처럼 단일 경로로 된 상태에서 길을 일어버릴 리 없다. 반면에 단일 경로는 각 장치를 연결하는 경로 중 하나가 단절되면 인터넷도 끊긴다는 치명적인 약점이 있다.
이런 문제를 해결하기 위해 고안된 것이 바로 그림의 오른쪽에 표시된 것과 같은 이중화 경로이다. 그림과 같이 연결되어 있는 경우라면 스위치 1과 3을 연결하는 경로가 단절될 경우 스위치 2와 3을 통해 인터넷에 접속할 수 있어 인터넷 고립의 문제를 해소할 수 있다.
하지만 이 방법에도 문제가 없는 것은 아니다. 같은 브로드캐스트 도메인 내에서 그림과 같은 형태의 이중화 경로로 구성하면 루핑이 발생하는 탓이다.
<그림 15>과 같은 구성에서 사용자가 만약 브로드캐스트 프레임을 스위치1과 2으로 보낼 경우 스위치2는 스위치1로, 스위치1은 다시 스위치2로 재전송하게 된다. 이런 동작이 계속 반복되면서 각 스위치들이 브로드캐스트를 계속 보내기만 하는 루프 현상이 발생하고 결국 브로드캐스트 스톰으로 이어지기까지 한다.
브로드캐스트 스톰이 발생하면 일반적으로 스위치가 다운되거나 시스템에 지나친 부하가 발생하여 스위치가 다운되는 것이다. 또한 잘못된 MAC 테이블이 생겨서 네트워크 상의 통신에도 오류가 발생한다. 이런 루핑과 관련한 일련의 문제들을 해결하기 위해 사용하는 것이 바로 지금부터 알아볼 스패닝 트리(Spanning-Tree)이다.
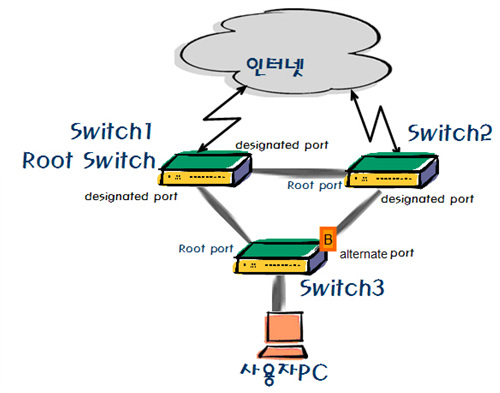
스패닝 트리란 <그림 16>처럼 이중화로 연결된 링크 중에 하나에는 트래픽이 흐르지 못하도록 막는 방법이다. 이처럼 두 경로 중 하나를 차단하여 루핑을 방지하고 트래픽이 흐르고 있던 경로에 문제가 생겼을 때 막았던 경로를 열어서 통신할 수 있도록 설계된 기술을 STP(Spanning Tree Protocol)이라고 부른다.
시스코 스위치에서 스패닝 트리를 Enable 하려면 다음과 같은 명령어를 입력한다.
Switch(config)#spanning-tree vlan <번호>
Switch(config)#spanning-tree vlan <번호> priority [0~61440] VLAN 우선순위 일반적으로 root는 mac으로 결정하나 priority를 주어 root port를 지정할 수 있다.
네트워크의 장애 유형은 장비의 전원불량, 네트워크 회선이나 케이블 문제, 장비 문제, 라우팅 문제 등 아주 다양하다. 하지만 필자의 경험을 바탕으로 생각해보면 대부분의 문제들 중 90% 정도는 UTP케이블이나 사용자 애플리케이션에서 발생한다. 당연히 괜찮을 것 같은 곳에서 문제가 발생할 수 있다는 이야기다. 약간의 주의를 기울이면 대형장애를 예방할 수 있음을 잊지 말자. @
도움주신 분 인네트 : 배원식님, 윤성업님, 최재혁님
참고자료
시스코 홈페이지 http://www.cisco.com
네이버 네트워크 전문가 따라잡기 http://cafe.naver.com/neteg
네이버 백과 사전 http://100.naver.com
차순태님 블로그 http://blog.naver.com/lemonaroma98
* 이 기사는 ZDNet Korea의 제휴매체인 마이크로소프트웨어에 게재된 내용입니다.





