2004년이 아직 많이 남아 있지만 지금까지 있었던 올해의 일들을 되돌아보면 그것은 매우 달콤하고 강렬한 꿈의 연속과도 같았다. 2000년부터 시작해 온 오픈소스 프로젝트가 가시적인 결실을 맺은 해이기 때문이다.
실무에서도 많은 일이 있었지만 무엇보다도 그 밑거름이 되어 온 필자의 오픈소스 프로젝트 경험담을 독자 여러분과 나누고자 한다(편집자 주 : 이 글이 작성된 시점은 지난해 11월이다).
오픈소스 프로젝트를 하기로 처음 결심한 것은 지난 2000년 한국어판으로 발매된『OPEN SOURCES』(한빛미디어)라는 책을 읽고 나서였다. 4년이 지난 지금 자세한 내용은 기억할 수 없지만 그 책은 무엇보다도 오픈소스 프로그램을 만든다는 것이 얼마나 재미있고 또 실제로도 유용한지를 흥미진진하게 설명해 주었다.
이런 매력적인 오픈소스 모델은 C 언어를 갓 배운 중학교 시절 한글 입출력 라이브러리 제작으로 시작된 라이브러리에 대한 관심과 자연스럽게 결합했고 당시 서버 프로그래밍을 하고 있었던 필자는 누구나 서버 개발에 유용하게 쓰일 만한 공용 툴킷을 개발하기로 했다.
라이브러리(그것이 프레임워크이든 툴킷이든)의 개발은 개발자에게는 매우 중요한 경험이다. 일반 사용자를 위해 윈도우용 애플리케이션을 만들 때 고려해야 할 것이 유저 인터페이스라면, 라이브러리 개발시 고려해야 할 것은 바로 API다. 라이브러리의 API가 얼마나 개발자의 요구에 부합하느냐에 따라 라이브러리의 유용성이 1차적으로 판가름나고, 그 뒤에 라이브러리의 풍부한 기능과 성능이 따라온다.
그런데 이 API라는 것이 라이브러리에만 있는 것이 아니다. 그것은 바로 우리가 일상적으로 개발하고 있는 모든 비즈니스 로직에 있기에 필자는 라이브러리 개발 경험을 매우 중시한다.
이 때 개발된 라이브러리는 자바서비스넷(javaservice.net)에 몇 차례 공개되었고, 나중에 더 많은 프로젝트를 진행하면서 개량되어 소스포지(milkbox.sf.net)나 개인 홈페이지(gleamynode.net/dev)에 등록되었다. 그러나 자바 커뮤니티가 나날이 성숙해지자 이러한 노력은 ASF(Apache Software Foundation, www.apache.org)과 같은 역사를 가진 비영리 기관에서부터 CodeHaus(www.codehaus.org), OpenSymphony(www.opensymphony.com) 등과 같은 상대적으로 새로운 기관 등에 집중되기 시작했으며, 서서히 개인의 차원을 넘어서게 되었다.
학업과 프로젝트를 병행하면서 눈코 뜰 새 없이 바쁜 나날을 보내던 중 필자가 개발했던 것들이 AJC(Apache Jakarta Commons, jakarta.apache.org/commons)와 같은 프로젝트에서 커뮤니티의 후원 속에 발전하고 있다는 것을, 그리고 필자는 그 곳에 참여하지 않고 있었음에 안타까운 마음이 들었다.
흥미진진한 오픈소스 프로젝트, Netty 2
이와 같았던 Netty 1은 이미 2001년경부터 여러 프로젝트에서 사용되어 왔으나 필자의 홍보 및 문서화, 그리고 경험 부족으로 커뮤니티의 지원이 전혀 없었다. 그런 실수를 거울삼아 다시 시작한 프로젝트가 바로 Netty 2다. Netty 2는 Netty 1의 메이저 업데이트 버전으로 Netty 1이 J2SE 1.3 이하의 BIO(Blocking I/O) API를 사용했던 반면 Netty 2는 J2SE 1.4 이상부터 지원되는 NBIO(Non-blocking I/O) API를 사용했다.
당시 J2SE 1.4가 활발하게 사용되기 시작했지만 제대로 된 NIO 프레임워크는 없었고 간혹 나온다 해도 알파나 베타 수준에서 머무르고 있었다. 이는 아마도 오늘날 대부분의 개발이 웹에 치중되어 있기 때문이라는 생각이 든다. 그러나 특수 목적의 서버를 개발하거나 레거시 시스템과 연동하는 등의 일들도 프로젝트에서 충분히 많은 시간을 소요한다. 특히 프로토콜의 구현이 그러했다.
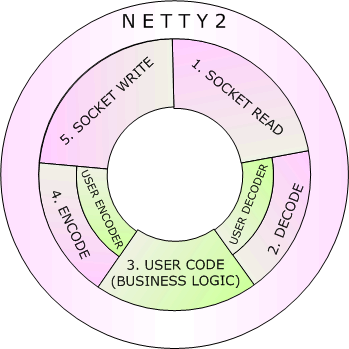
Netty 시리즈의 개발 목표는 바로 이러한 저수준 I/O 호출을 숨기고, 그것을 이벤트 기반(Event-Driven) 방식으로 전환해 주는 것이었다(<그림 1>).
당시 필자는 이동통신 3사에 SMS 전송을 하는 SMS 센터를 개발하고 있었는데, 이들 3사는 통신 상의 논리적 흐름(이하 메시지 플로우)이나 메시지 (전문) 유형은 모두 동일했지만, 전문의 인코딩은 전부 제각각이었다. 어떤 기업은 network byte order의 바이너리 데이터를 원했고, 또 다른 기업은 ASCII 문자열을 원했다. ASCII 문자열일 경우에도 남는 공간은 공백으로 채울지, 아니면 NULL로 채울지 여부도 제각각인 등 필자를 피곤하게 하였다.
하지만 만약 프로토콜 상의 메시지들이 추상화된 개체로 표현이 되고, 이것이 이벤트처럼 전달된다면 어떨까? 상기 유즈 케이스의 경우 엄청난 이득이 있다.
첫째, 메시지 플로우는 같으나 메시지의 인코딩이 다르다면 메시지를 인코드/디코드하는 부분과 메시지 플로우를 다루는 부분을 따로 개발할 수 있다(<그림 1>의 유저 인코더/디코더). 또한 메시지 플로우를 다루는 코드는 한 번만 구현하면 이동통신 3사의 프로토콜을 매우 쉽게 구현할 수 있다(<그림 1>의 유저 코드). 이 장점은 시간이 흐른 후 이동통신 3사 이외의 다른 SMS 전송 서비스 업체로의 메시지 전달을 구현하는 데 위력을 발휘했다.
둘째, 이벤트는 기본적으로 비동기 방식이다. 메시지를 비동기로 주고받도록 프로그램하는 것은 숙련된 개발자의 기술이 필요하다. 이벤트 기반으로 네트워크 I/O를 자동으로 수행하고 그것을 개체로 전달할 수만 있다면 사용자가 복잡한 네트워크 프로그래밍 지식 없이도 숙련자의 것에 못지않은 결과를 낼 수 있다. 다음은 Netty 2의 예시 프로그램인 SumUp 클라이언트/서버 중 서버의 일부로 상기 특징을 잘 표현하고 있다.
/*
* @(#) $Id: ServerSessionListener.java 18 2004-08-21 08:27:49Z trustin $
*/
package net.gleamynode.netty2.example.sumup;
import net.gleamynode.netty2.Message;
import net.gleamynode.netty2.Session;
import net.gleamynode.netty2.SessionListener;
import net.gleamynode.netty2.SessionLog;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
/***
* {@link SessionListener} for SumUp server.
*
* @author Trustin Lee (http://gleamynode.net/)
* @version $Rev: 18 $, $Date: 2004-08-21 17:27:49 +0900 (토, 21 8월 2004) $
*/
public class ServerSessionListener implements SessionListener {
private static final Log log = LogFactory
.getLog(ServerSessionListener.class);
public ServerSessionListener() {
}
public void connectionEstablished(Session session) {
SessionLog.info(log, session, Connection established.);
// set idle time to 60 seconds
session.getConfig().setIdleTime(60);
// initial sum is zero
session.setAttachment(new Integer(0));
}
public void connectionClosed(Session session) {
SessionLog.info(log, session, Connection closed.);
}
public void messageReceived(Session session, Message message) {
SessionLog.info(log, session, RCVD: + message);
// client only sends AddMessage. otherwise, we will have to identify
// its type using instanceof operator.
AddMessage am = (AddMessage) message;
// add the value to the current sum.
int sum = ((Integer) session.getAttachment()).intValue();
int value = am.getValue();
long expectedSum = (long) sum + value;
if (expectedSum > Integer.MAX_VALUE
< Integer.MIN_VALUE) {
// if the sum overflows or underflows, return error message
ResultMessage rm = new ResultMessage();
rm.setSequence(am.getSequence()); // copy sequence
rm.setOk(false);
session.write(rm);
} else {
// sum up
sum = (int) expectedSum;
session.setAttachment(new Integer(sum));
// return the result message
ResultMessage rm = new ResultMessage();
rm.setSequence(am.getSequence()); // copy sequence
rm.setOk(true);
rm.setValue(sum);
session.write(rm);
}
}
public void messageSent(Session session, Message message) {
SessionLog.info(log, session, SENT: + message);
}
public void sessionIdle(Session session) {
SessionLog.warn(log, session, Disconnecting the idle.);
// disconnect an idle client
session.close();
}
public void exceptionCaught(Session session, Throwable cause) {
SessionLog.error(log, session, Unexpected exception., cause);
// close the connection on exceptional situation
session.close();
}
}
이 코드는 클라이언트의 AddMessage가 담고 있는 정수를 모두 더한 지금까지의 합을 응답 메시지로 되돌린다. 어디에도 SocketChannel.read()나 write() 메쏘드가 보이지 않는다. 그러나 이것은 명백히 네트워크 서버다. 여러 서버 애플리케이션에서 이러한 테크닉이 사용되고 있으나, Netty는 이것을 일반화하고 정제하여 실제로 사용 가능한 API를 만들어내었다.
그러나 이러한 좋은 프레임워크가 있다 하더라도 많은 사람들이 사용하지 않으면 그 유용성은 떨어진다. 과거의 쓰라린 경험을 거울삼아 필자는 이를 본격적으로 홍보하기로 했다. 그 전략은 다음과 같다.
◆ 모든 작업을 영어로 진행한다.
◆ Netty 2가 높은 인지도를 얻기 위해서는 전 세계적인 참여가 필요하다고 판단했기 때문에 모든 문서와 주석을 영어로 작성하였다.
◆ 멋진 룩앤필의 웹 사이트를 만들고 포럼을 연다.
◆ 웹 사이트는 Maven(maven.apache.org)이라는 지능형 프로젝트 빌드 시스템의 등장으로 가능해졌다. 당시 오라일리 OnJava.com의 Maven에 관한 튜토리얼을 읽은 것이 계기가 되어 사용하게 되었는데, 결과는 대 만족이었다. 필자는 거의 모든 프로젝트를 Maven으로 빌드하고 있다.
◆ 포럼은 외국인들이 선호하는 phpBB(www.phpbb.com)를 사용했다.
◆ 버그 트랙커는 Mantis(mantisbt.sf.net)을 사용하고 싶었으나 게으름으로 적용하지 못했지만 포럼에 버그 리포팅 게시판이 따로 있어 별다른 어려움이 없었다.
◆ 유명 사이트에 릴리즈 소식을 알리고 사람들의 관심과 답글에 친절히 대답한다.
이와 같은 목표를 갖고 Netty 2를 개발한 지 수 개월이 지나 어느 정도 안정적인 버전이 개발되었다. 2004년 6월 7일, 필자는 용기를 내어 TheServerSide.com에 Netty2 버전 1.0.0의 릴리즈를 알렸다. 그러나 그 결과는 썩 좋지 못했다. 그들은 너무나 정직했다.
The usefulness of Netty is zero when the documentation is so poor. - Han Theman
필자는 Netty가 사장되지는 않을까 걱정이 되었고, 3일에 걸친 작업 끝에 JavaDoc을 상세히 보강하고 예제 코드와 전체적인 UML이 포함된 튜토리얼을 추가해 버전 1.1.0을 릴리즈했다.
TheServerSide.com에서는 릴리즈 알림을 한 달에 1회로 제한하고 있었기 때문에 필자는 Freshmeat.net(www.freshmeat.net)을 이용하기로 했고, 이것은 매우 효과가 좋았다. 지금은 50여명에 이르는 개발자들이 Netty의 새 버전이 릴리즈될 때마다 Freshmeat이 자동으로 발송하는 메일을 수신하고 있다.
지속적인 기능 개선과 릴리즈가 계속되면서 포럼에 하나 둘 질문이 올라오기 시작했다. 처음에는 “Netty와 JMS와의 관계가 어떻게 됩니까?”, “컴파일이 안됩니다”, “어떻게 실행하죠?” 등의 질문이었지만 그것도 잠시였다. 그리고 얼마 지나지 않아 필자는 커뮤니티가 가진 힘을 실감했고 그 위력에 감탄할 뿐이었다.
첫째, 버그를 잡으려 애쓰지 않아도 버그 리포트가 들어온다. 이것은 Netty를 정말로 안정적으로 사용할 수 있게 바꾸어 놓았다. 1.0이 릴리즈 되었지만 정말 많은 버그를 내포하고 있었음이 사용자들에 의해 발견되었다. 어떤 사용자는 심지어 Netty의 소스코드를 디버그하여 어떤 부분이 잘못되었는지를 지적해 주거나, JDK 1.4 초기 버전의 버그를 돌아가는 방법(workaround)까지 제시했다.
둘째, 사용자의 요구(Feature Request)로 Netty가 어떤 기능이 부족한지 알게 되었다. 예를 들면 다음과 같다.
◆ UDP의 지원
◆ 속도가 느린 클라이언트의 탐지
◆ API의 결함이나 누락된 메쏘드
◆ 사용자가 버그를 만들 수 있는 문서의 미비한 부분(FAQ 작성)
필자가 보지 못했던 것들을 필자는 커뮤니티의 눈을 통해 보았고, 이는 Netty를 지속적으로 개선시키는 힘이 되었다. 그리고 무엇보다도 그 과정은 너무나 흥미진진하여 매일같이 Netty 생각만 하게 만들어버릴 정도였다. 그렇다. 오픈소스는 즐겁다 못해 행복하다!
비즈니스 로직 처리를 위한 OIL
네트워크 클라이언트/서버의 개발은 이제 Netty의 사용으로 손쉬워졌다. 필자의 한 해는 이렇게 Netty와 함께 행복하게 끝날 것 같았지만 비즈니스 로직을 처리하는 서버는 또 다른 무언가를 필요로 했다. 바로 '작업 큐'다. 많은 서버들이 이를 단순한 순환 큐(circular queue)나 파일 기반 큐, 또는 관계형 데이터베이스에 저장한다. 하지만 이들은 모두 다음과 같은 문제를 갖고 있다.
◆ 순환 큐는 메모리 상에서만 유지되므로 서버를 종료한 뒤에 이를 복구할 수 없다. 또한 큐의 내용을 특정 키 값으로 검색할 수 없다(선형 시간이다).
◆ 파일 기반 큐는 적절한 캐싱을 하지 않을 경우 성능에 문제가 있다. 마찬가지로 큐의 내용을 특정 키 값으로 검색할 수 없다.
◆ 관계형 데이터베이스는 모든 요구를 충족하지만 응답 속도가 늦다.
세 가지 솔루션을 하이브리드하게 사용하여 효과를 볼 수도 있겠지만 이 모든 요구를 충족하는 라이브러리가 있다면 금상첨화이기에 필자는 이를 만들고 오픈소스로 공개하기로 마음먹었다.
OIL(Objects in a Line)은 오늘날 대부분의 MOM(Message-Oriented Middleware)가 채택하고 있는 WAL(Write-Ahead Logging) 테크닉을 이용한 큐 라이브러리다. WAL이란 데이터 구조를 파일에 저장하는 대신 메모리에 있는 데이터에 대한 조작 동작을 로그화하여 순차적으로 기록하는 기법을 말한다. WAL을 이용한 큐는 다음과 같은 장점이 있다.
◆ 디스크의 한 지점에만 로그를 쓰고 파일 구조를 유지할 필요가 없으므로 데이터 조작 성능이 우수하다.
◆ 모든 데이터가 메모리에 적재되므로 데이터 조회 성능이 매우 우수하다.
그러나 다음과 같은 단점도 있으나 해결 가능하다.
◆ 모든 데이터가 메모리에 적재되므로 대량의 메모리가 필요할 수 있다. 그러나 오늘날의 메모리는 저렴하므로 데이터의 양이 매우 많지 않은 이상 안전하다.
◆ 로그 파일이 매우 커질 수 있다. 그러나 새벽과 같이 서비스가 한가한 시간대에 로그를 자동 최적화 (defragment)할 수 있다.
인덱싱 가능한 큐의 구현
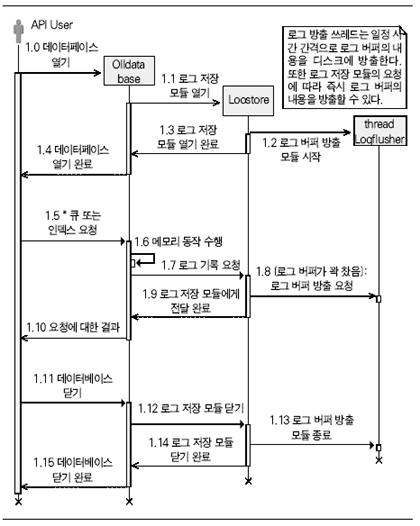
큐에 들어있는 데이터를 특정 키 값으로 검색하는 기능은 누구나 한 번쯤 필요로 하지만 구현하기가 쉽지 않은 기능이다. 예를 들어 클라이언트의 요청이 작업 큐에 들어와 있되 아직 처리되지 않았을 경우 클라이언트는 해당 요청의 처리 현황을 파악하고 처리가 지나치게 늦어진 요청만 선택적으로 취소할 수 있다. 이 과정에서 큐의 내용을 검색하는 것은 필수적이다.
검색을 할 수 있다는 것은 데이터의 위치를 지정할 수 있음을 의미한다. 그러나 일반적인 순환 큐 구현은 데이터의 위치 값이 큐 확장시마다 재지정되므로 검색이 불가능하다. 이를 해결하기 위해 <그림 2>의 구조를 택했다.
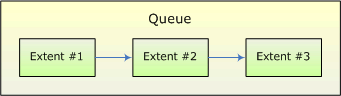
<그림 2>에서와 같이 큐는 여러 개의 extent로 구성되어 있는데, 각 extent의 내부는 <그림 3>과 같다.
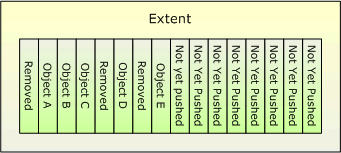
이 구조로 어떻게 데이터의 위치를 변하지 않게 할 수 있을까? 그 비밀은 extent의 ID와 extent 내에 위치한 개체들의 오프셋이 변하지 않는다는 데 있다. 즉, 큐가 포함하고 있는 데이터 항목의 위치는 extent의 ID와 extent 내의 오프셋 값으로 지정이 가능하다.
이미 알아챘겠지만, 이 방법은 extent 하나가 담을 개체의 최대 크기를 정해야 한다는 문제가 있다. 즉 extent의 크기가 65536인데 개체가 전부 삭제되고 한 개만 남아도 extent의 크기는 여전히 65536이기에 이렇게 데이터가 산발적으로 위치할 경우 메모리에 부담을 가져올 수 있다는 것이다.
이 문제를 해결하기 위해 extent의 크기를 줄인다면 extent의 수가 많아지고, 이를 관리하는 데 드는 비용이 증가하게 된다. 그러나 일반적인 서버에서 작업은 대체적으로 순차로 이루어지기 때문에 이 문제는 특정 경우에만 영향이 있다고 할 수 있겠다.
성능 향상을 위한 몸부림
아무리 WAL을 이용해 빠른 성능을 보장한다고 해도 성능을 위한 몸부림은 계속되었다. 큐를 여러 개 사용하는 애플리케이션의 경우 큐와 큐 사이의 데이터를 이동하는 일이 빈번하다. 메모리 상에서의 작업만 존재한다면 이를 pop와 push 동작을 연속시켜 해결하겠지만, WAL에서는 중요한 문제가 된다. Push 로그에 push할 개체를 디스크에 직렬화(serialize)해야 하기 때문이다.
이 문제를 해결하기 위해 도입된 것이 바로 'move' 동작이다. 즉, 어느 위치의 항목을 어느 큐로 이동했다는 단순한 move 로그만 남겨 성능 향상을 도모했다. 그러나 이 move 동작은 필자에게 매우 심한 스트레스를 가져왔는데, 그 이유는 이 동작이 메모리 상에서는 여전히 두 개의 동작으로 이루어져 있기 때문이었다.
최초의 구현은 단순히 2개의 동기화(synchronized) 블럭을 열고 데이터를 옮기는 것이었는데, 이것은 금방 문제를 가져왔다. 큐 A가 큐 B로, 큐 B가 큐 A로 데이터를 옮길 때 데드락이 발생하는 문제를 간과했기 때문이다. 이 문제를 해결하기 위해 락(Lock)할 개체를 hashCode 순으로 정렬하여 락을 거는 방법이 유력했으나 락 개체를 도입하기에는 수정할 분량이 너무 많아 포기하였다.
두 번째 구현은 동기화 블럭을 데드락이 생기지 않으면서 로그의 순서가 흐트러지지 않도록 교묘하게 2개로 나눈 것이었다. 이것은 처음에는 잘 동작하는 것으로 보였지만 추적이 매우 힘든 동시성 문제를 가져왔다. 큐의 데이터가 깨지지는 않았으나 로그가 순서대로 기록되지 않아 서버가 재시작할 때 데이터가 손실되었다.
세 번째 시도에서 필자는 이 문제를 근본적으로 해결하기 위해 OIL을 거의 새로 프로그래밍할 수밖에 없었다. 메모리 상에서 동작을 수행하는 부분과 디스크에 기록하는 부분을 완전히 분리하고 첫 구현에서 망설였던 락을 Doug Lea의 Concurrent 라이브러리 (
concurrent/intro.html target=zdnk>http://gee.cs.oswego.edu/dl/classes/EDU/oswego/cs/dl/util/ concurrent/intro.html
복잡한 동기화 블럭으로 얽힌 기존의 구현보다 코드가 깔끔해진 것은 물론이거니와 4개 이상의 CPU를 가진 시스템에서도 모든 CPU를 다 사용할 수 있게 되었다. 이를 통해 필자는 다음과 같은 중요한 교훈을 얻게 되었다.
◆ 자신이 직접 구현할 수 있다 하더라도 가능한 모든 곳에서 전문화된 패키지의 사용을 두려워 말라.
◆ 변화의 요구가 나타날 때 망설이는 것은 더 많은 어려움을 낳는다.
Checked Exception이냐, Unchecked Exception이냐
자바의 예외는 checked와 unchecked exception으로 나뉜다. 의외로 이 용어와 차이를 모르는 개발자가 많다. Checked exception은 IOException과 같이 반드시 try-catch 블럭으로 감싸 잡아줘야 하는 예외를 말한다. unchecked exception은 NullPointerException과 같이 RuntimeException을 상속하여 try-catch 블럭으로 감싸지 않아도 묵시적으로 던져질 수 있는 예외를 말한다. 자바의 checked/unchecked exception에 대한 논의는 오래된 것으로 Burce Eckel이 잘 정리한 다음 URL을 참고하면 좋을 듯하다.
그렇다면 OilDatabase가 던지는 OilException은 어디에 속해야 할까? 처음에 필자는 JDBC API를 참고하여 OilException을 checked exception으로 했지만, 큰 애플리케이션을 개발하게 되면서 고민에 빠졌다. 서버가 요청을 처리하기 위해 큐를 매우 빈번히 사용하는 탓에 여기저기 보기 흉하게 try-catch 블럭이 늘어나버렸기 때문이다.
큐의 동작이 실패한다는 것은 매우 치명적인 일이므로 OilException이 발생하게 되면 애플리케이션은 정상적인 동작을 할 수 없다. 따라서 대부분의 소스코드에서 OilException의 catch 블럭은 로그에 남기고 동작을 종료하는 등의 단순한 처리만을 수행하면서 소스를 복잡하게 보이게 했다.
결국 필자는 지금까지 개발된 코드의 수정을 감수하면서 OilException을 unchecked exception으로 변경했다. 시간이 지나자 그것은 '감수'가 아니라 올바른 선택으로 판명되었다. 예외 처리 창구는 일원화되고 보기 흉한 try-catch 블럭은 전부 사라져 다른 사람들도 OIL API를 좋아하게 되었다.
ASF으로부터의 연락
OIL을 정식 릴리즈하기 위해 문서화 작업을 시작하려고 할 즈음, 뜻하지 않은 연락을 받게 되었다. ASF의 Directory 프로젝트(incubator.apache.org/directory) 중 LDAP 서버인 Eve를 담당하고 있는 Alex Karasulu는 Netty 2 포럼에서 활동했던 Enrique Rodriguez가 개발한 Kerberos 서버에 관심을 갖고 있었다.
Alex는 Enrique의 Kerberos 서버의 Directory 프로젝트 편입을 희망했고, 따라서 자신이 진행해 온 SEDA 프로젝트와 전체적인 로드맵을 함께 설명했다. Enrique는 SEDA가 하는 일을 제공하는 좋은 프로젝트가 이미 있고, 그것이 자신이 Kerberos 서버를 개발하는데 사용한 Netty 2라는 것을 밝힌다.
Alex는 Netty 2의 구현 상태에 매우 관심을 보이며, 함께 Netty 2의 기능과 SEDA(Staged Event Driven Architecture)의 아키텍처를 혼합한 유닉스의 inetd와 같은 네트워킹 플랫폼을 개발할 것을 제안했다. 가슴 두근거리는 제안이 아닌가! 필자는 바로 승낙했고, 그는 필자를 ASF에 적극 추천하여 정식 커미터로 만들어 주었다.
정식 커미터가 되기 위해서는 보통 해당 ASF 프로젝트에 대한 눈에 띄는 공헌이 필요했지만 Alex의 도움으로 몇 가지 간단한 패치를 만들고 메일링 리스트에서 활동한 것만으로 PMC 투표를 통과했다. Alex는 한글을 모르지만 이 자리를 빌어 그의 끊임없는 격려와 조언에 진심으로 감사하고 싶다.
필자는 지금도 첫 번째 커밋의 순간을 잊을 수가 없다. ASF의 일원이 되어 SEDA라는 TLP(Top Level Project)를 이끌게 될 생각을 하면 가슴이 두근거리는 것이다. 하지만 무엇보다도 멋진 순간은 전 세계에 흩어진 필자보다 훨씬 더 많은 경험을 가진 여러 분야의 사람들과 함께 비전을 공유하고 서로에게서 많은 것을 배우고 협동하는 동시에 또 경쟁하게 될 바로 지금일 것이다. @
* 이 기사는 ZDNet Korea의 자매지인 마이크로소프트웨어에 게재된 내용입니다.